本文主要讲述kafka topic的创建流程,所有的代码基于kafka_2.10-0.8.2.1。
kafka topic 创建流程
首先,kafka topic的创建是有两种方式的,关于具体的方式请参考博文Kafka Topic Partition Replica Assignment实现原理及资源隔离方案.
当用户执行如下面的代码的时候1
$ bin/kafka-topics.sh --create --zookeeper zookeeperip:2181 --replication-factor 2 --partitions 10 --topic testtopic
打开kafka-topics.sh文件,会发现如下图片
说明,创建topic的时候,走的是kafka.admin.TopicCommand接口,在这个接口中,所有的入口都是如下所示的main函数
然后根据解析的命令,走到createTopic(zkClient, opts)方法,下面是createTopic方法的代码
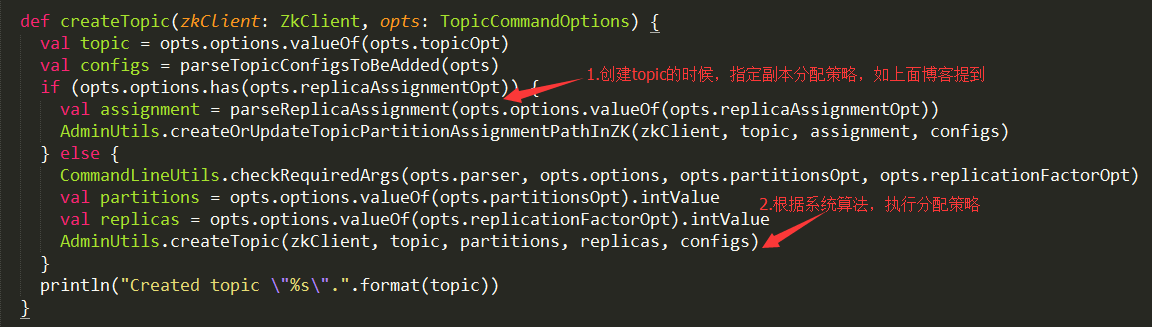
由上面的代码可以看出,此处可以有两种创建topic的方式,如博文Kafka Topic Partition Replica Assignment实现原理及资源隔离方案所讲。实际上,第二种创建topic的方式就是由按照系统分配算法,来决定关于这个topic的所有的partition的副本数具体落在哪些broker上面。所以,第二种创建方式最终都会走到AdminUtils中的createOrUpdateTopicPartitionAssignmentPathInZK方法。所以,这里着重讲述第二种创建topic方式走的流程。
我们看到,在TopicCommand中的createTopic中,首先解析了命令行中的partition的数量以及replicas副本的参数,并把这些参数传给了AdminUtils中的createTopic方法,下图是AdminUtils中的createTopic方法。
在AdminUtils中的createTopic方法中,系统主要做了3件事,1:从zookeeper中获取所有的集群中broker的列表。2:根据第一步获取到的broker列表,以及传过来的partitions和和replicationFactor,按照系统分配算法对每个partition进行分配。3:当前两步完成后,把所做的更改在zookeeper中修改,然后根据zookeeper的callback(回调),kafka自身会进行数据的迁移等等工作。
下面分别看下这三步,第一步,从zookeeper获取集群中所有的broker列表。进入到kafka.utils.ZkUtils类中的getSortedBrokerList方法,然后getSortedBrokerList调用java包中的ZkClient中的getChildren方法,传进去的参数path=“/brokers/ids”。一句话概况就是从zookeeper中获取/brokers/ids节点下面的所有的brokers。
关于第二步,分配策略。上面提及的博文讲解非常详细,具体请参考此博文。
下面,我们来看看第三步到底干了什么事情,下面是第三步执行的代码: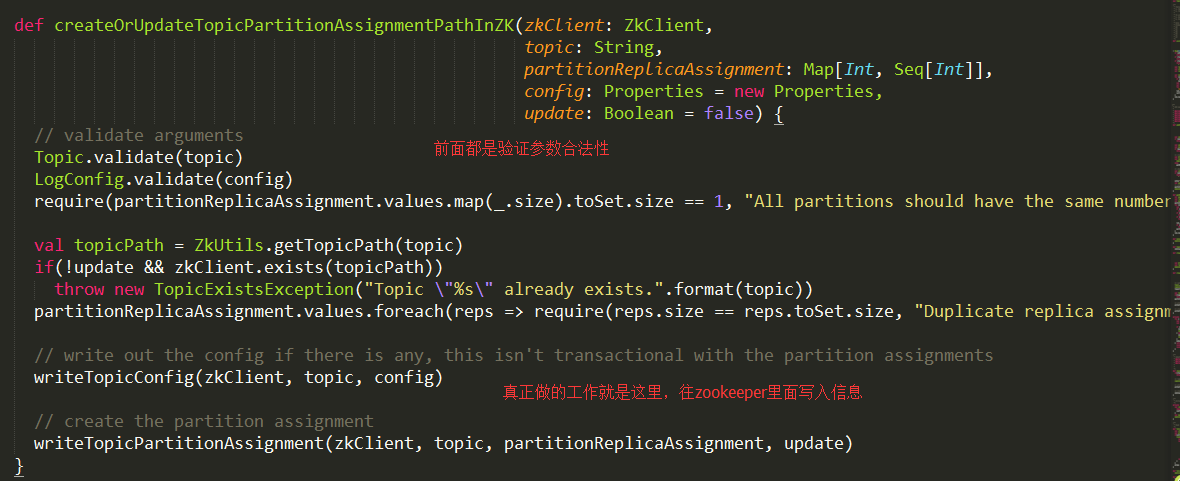
从代码中可以看出,主要做的工作就是最后面的两个方法,writeTopicConfig以及writeTopicPartitionAssignment。
writeTopicConfig最终走到了ZkUtils中的updatePersistentPath方法。而writeTopicPartitionAssignment最终走到了ZkUtils中createPersistentPath的方法,最后,ZkUtils最终跟java包中的ZkClient交互,修改或是添加zookeeper中节点的信息。kafka就是利用了zookeeper中的回调函数的概念,当zookeeper中节点变化的时候,kafka会感知变化,然后对数据做出相应的变化。
下面时序图是对上面分析的一个总结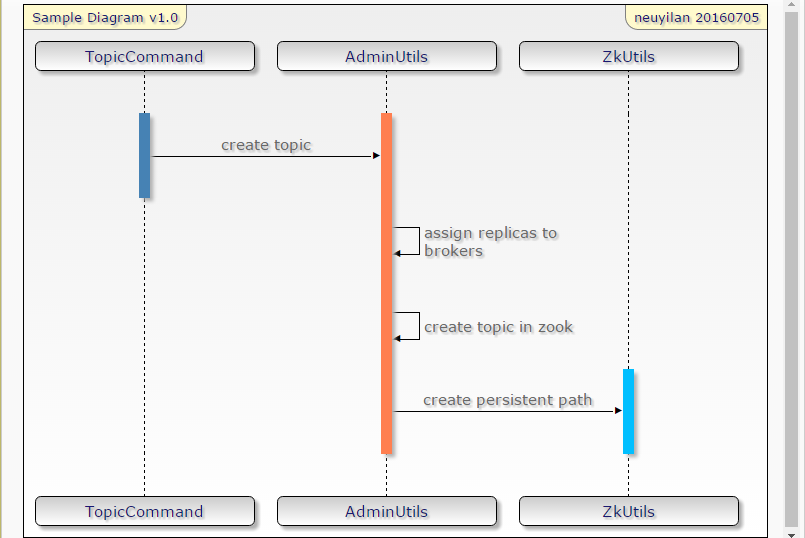
小结
有了上面的这些基础,所以,kafka中集群的概念就变的微不足道了。我们可以根据自己的生成策略,对topic的任意分区,可以指定到任意的机器broker上面,这就使得用户client有了很大的自主权利,特别是对于那些异构集群来说,或是某些业务场景比较重要,某些业务场景比较次要。这就可以对特定业务进行隔离,使得当不得不kill掉某些业务的时候,可以不牵扯到比较重要的业务。