Log 相关
log
log记录了集群中发生过的操作,每一条log都有如下4个变量:
| 属性 | 含义 | |
|---|---|---|
| currLogIndex | 此条log的索引 | |
| currLogTerm | 此条log的term | |
| previousLogIndex | 前一条log的索引 | |
| previousLogTerm | 前一条log的term |
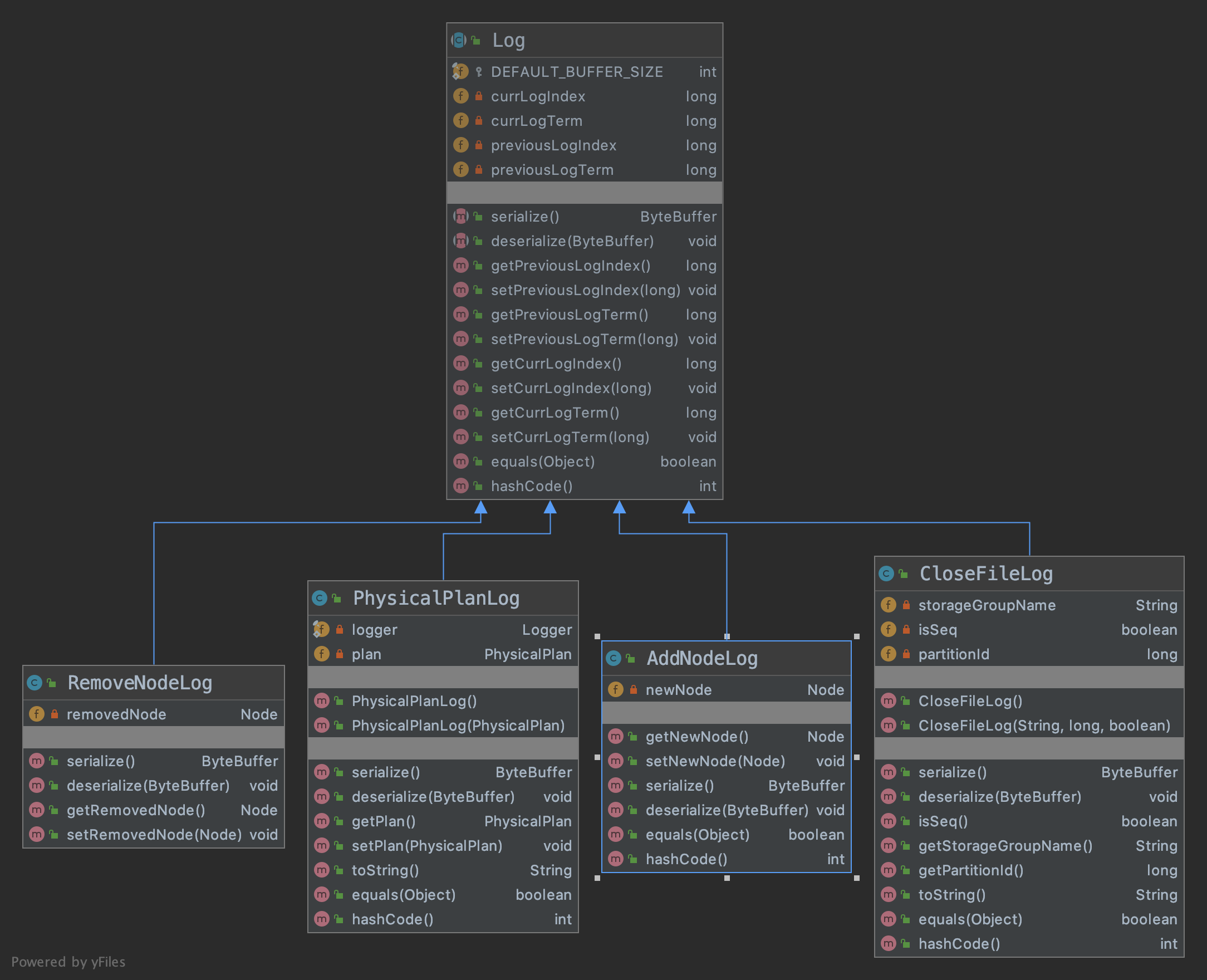
类图非常清晰了,无需详细解析,目前支持4种类型的log:1.AddNodeLog; 2.RemoveNodeLog; 3.CloseFileLog; 4.PhysicalPlanLog
snapshot解析
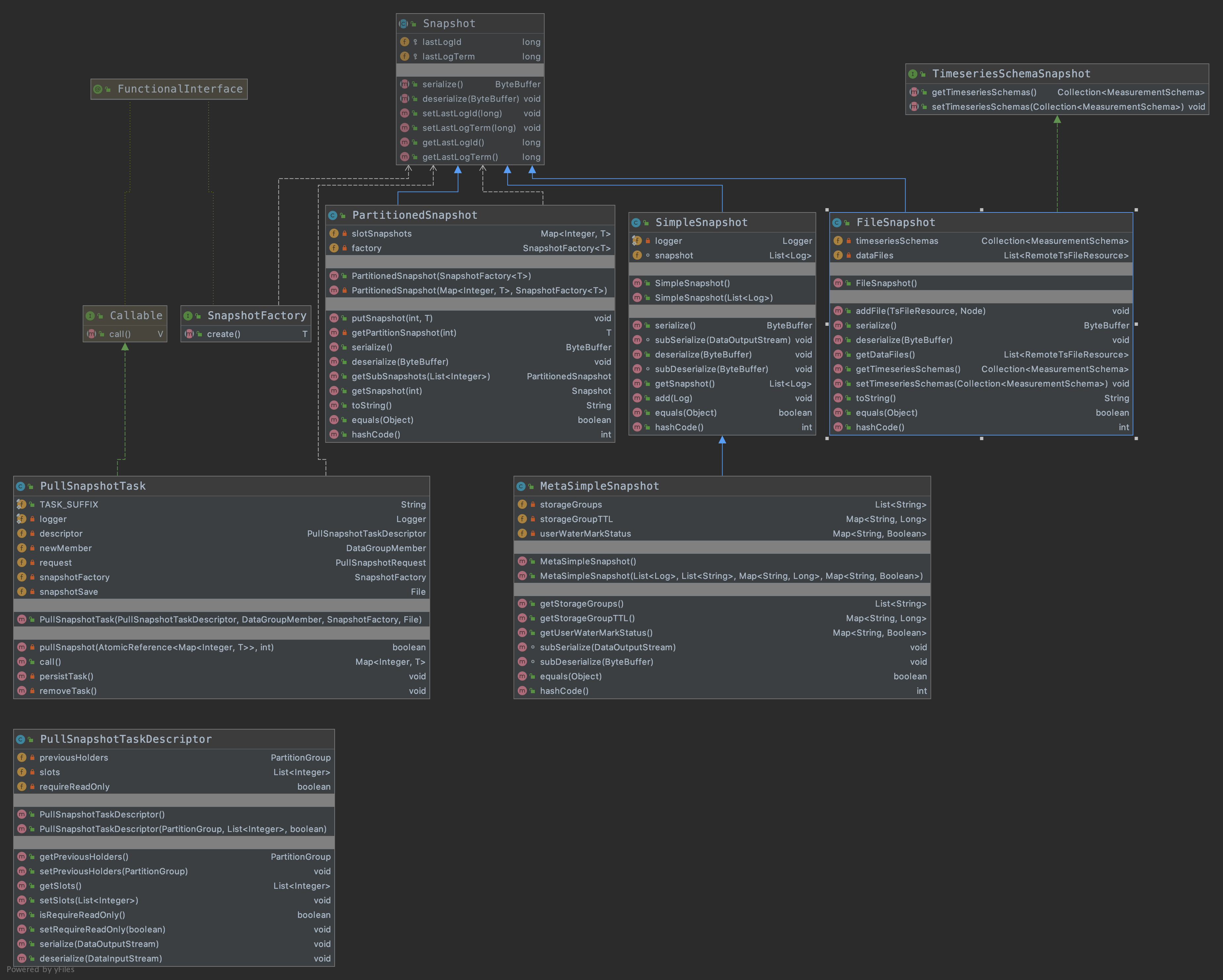
- 所有的snapshot都继承自父类Snapshot,父类有两个成员变量:lastLogIndex和lastLogTerm,指的是快照中最后的一条logid和log term
- SimpleSnapshot: 是最简单的快照实现方式,所有的log都保存在内存中,快照是一个list
的数组实现方式。 - FileSnapshot:继承了Snapshot的同时,也实现了TimeseriesSchemaSnapshot接口,主要保存了两个属性:
1
2private Collection<MeasurementSchema> timeseriesSchemas
private List<RemoteTsFileResource> dataFiles
RemoteTsFileResource是tsfile的文件描述,而MeasurementSchema也是描述的各个measurement。所以可以看出来FileSnapshot之所以称之为”文件快照“,主要是由于保存了TsFileResource的原因。
PullSnapshotTaskDescriptor:首先看一下官方注释:PullSnapshotTaskDescriptor describes a pull-snapshot-task with the slots to pull., 有如下两个数据结构.
1
2private PartitionGroup previousHolders;
private List<Integer> slots;PartitionedSnapshot: 使用一个map保存了每个slot id对应的快照。核心数据结构如下
1
2
3
4
5// key是slot id,value是Snapshot的泛型(具体的某一种Snapshot)
private Map<Integer, T> slotSnapshots;
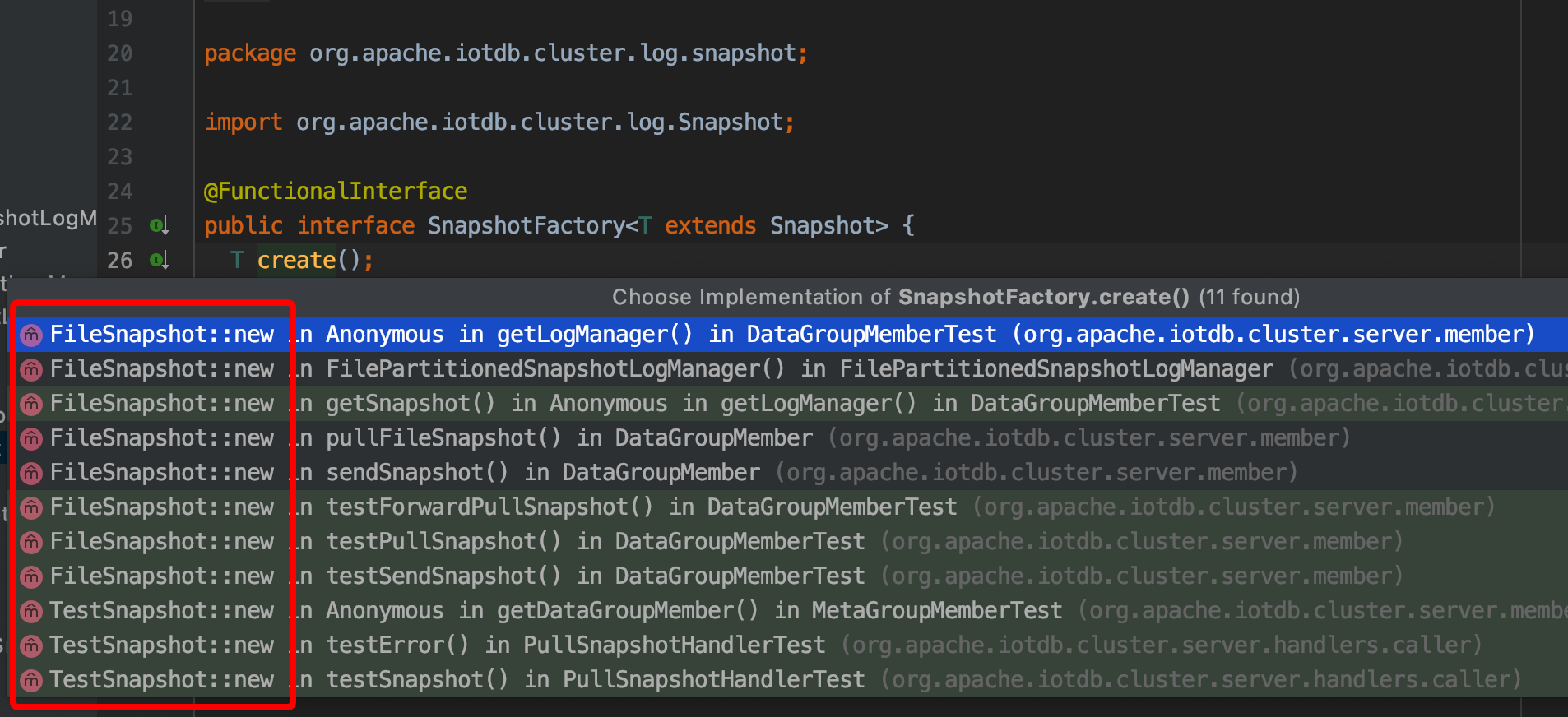
// SnapshotFactory是一个函数式接口,用来反序列化的时候创建Snapshot的实例,
// 可以通过下图看到函数接口的实现都是Snapshot的默认构造函数。
private SnapshotFactory<T> factory;
- MetaSimpleSnapshot:继承自SimpleSnapshot:多了一个属性storageGroups,保存了所有的storageGroups。除了需要保存storageGroups之外,MetaSimpleSnapshot还需要保存所有需要的元数据,例如ttl,dataAuth等。
- PullSnapshotTask, 他并不是一个快照的实现类,而是封装了执行快照任务的一个类,它实现了Callable接口,可以简单的理解为实现了Runnable接口一样,关于Runnable和Callable接口的差异请google。call 函数是具体实现pullSnapshot 任务的函数,返回值是一个map,key是slot id,value是snapshot,以供调用者可以读取snapshot的数据来进行数据追赶。PullSnapshotTask持有PullSnapshotTaskDescriptor,用来描述从哪儿拉取快照。
log applier
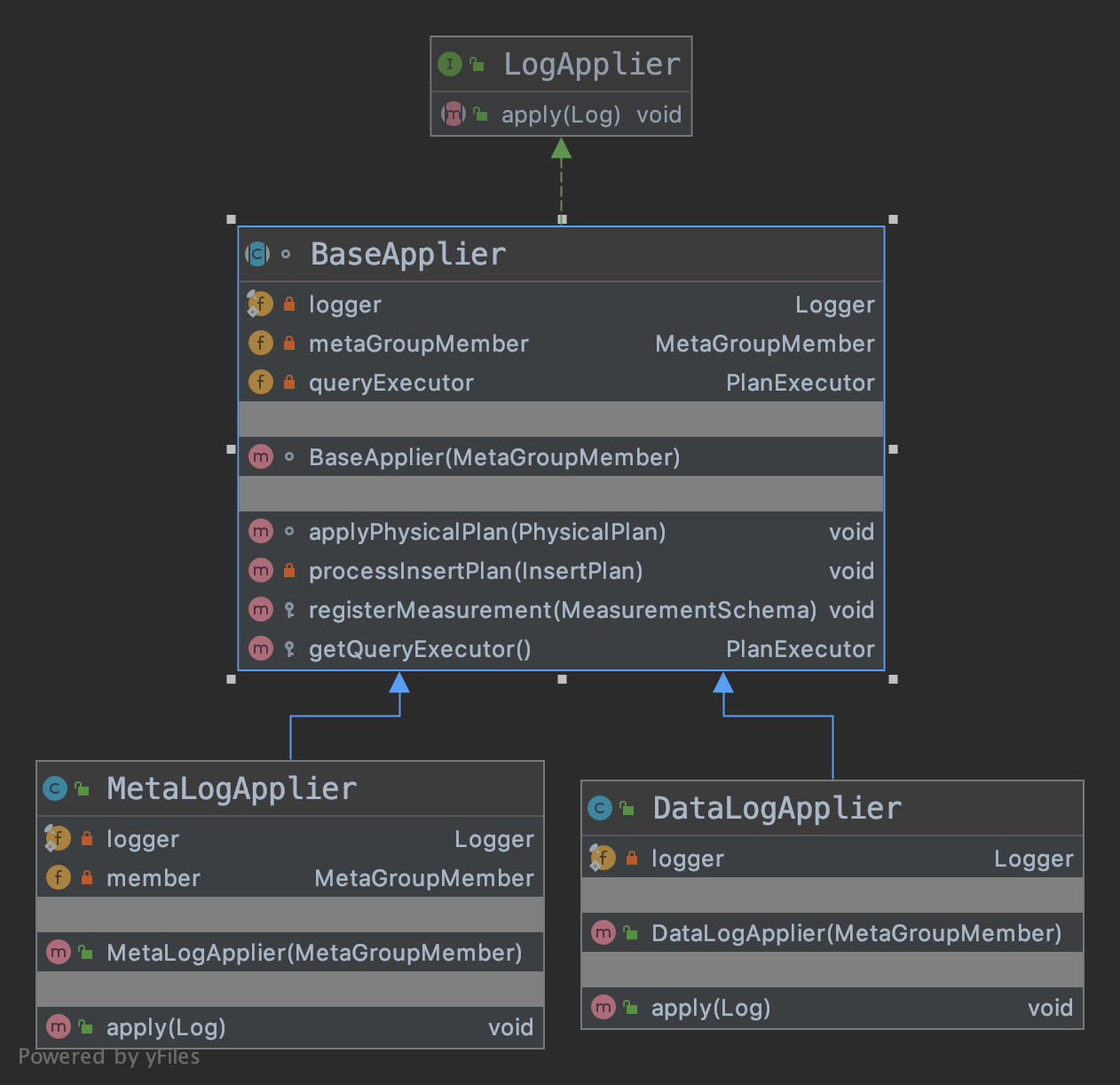
核心函数就是apply(Log),使得log所描述的action在本机生效,这里其实跟wal有点类似了,wal的作用就是执行任何事情之前先写wal,防止崩溃的时候wal可以恢复,只不过log applier是raft状态机中的组件。
DataLogApplier目前提供的apply类型:PhysicalPlanLog和CloseFileLog
MetaLogApplier目前提供的apply类型:AddNodeLog,RemoveNodeLog和PhysicalPlanLog。
两种都提供PhysicalPlanLog,会根据具体提供的操作(数据操作、元数据操作)不一样而执行不同的方法。
log manager
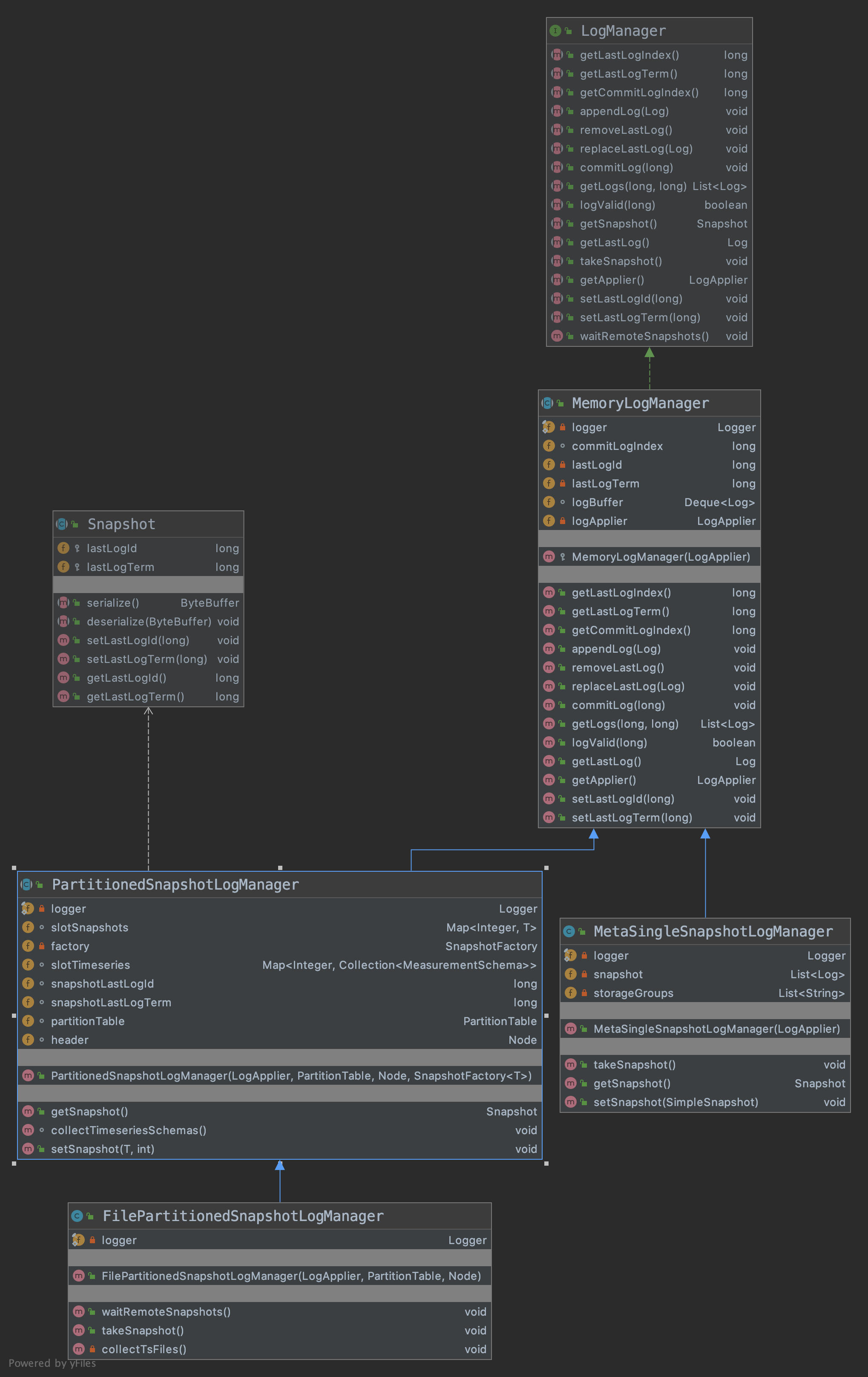
log manager也就是管理log的一些类,也就是log 存在哪里,怎么存?怎么取?等,目前的实现都是基于内存的实现方式。如果一个复制组所有的节点都crash的话,则log也就丢失了,基于文件(可持久化)的log管理目前正在开发中(https://issues.apache.org/jira/browse/IOTDB-351)
LogManager接口,主要提供了一些访问Log类属性的一些方法以及存储,读取log的一些函数。其中着重指出void commitLog(long maxLogIndex)函数,此函数会调用log applier中的apply函数。主要函数如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 追加一条log,目前实现是在内存中的logbuffer中追加一条log,
// 并且更新lastLogId以及lastLogTgiterm
boolean appendLog(Log log);
// 应用(apply) maxLogIndex之前的所有的日志
void commitLog(long maxLogIndex);
// 用于判断logIndex这条log是否还在内存中,如果不在内存中,说明已经形成快照了
boolean logValid(long logIndex);
Snapshot getSnapshot();
/**
* Take a snapshot of the committed logs instantly and discard the committed logs.
*/
// 把commitIndex之前的日志形成快照,并且删除commitIndex之前的日志。
void takeSnapshot() throws IOException;
LogApplier getApplier();
void setLastLogId(long lastLogId);
void setLastLogTerm(long lastLogTerm);MemoryLogManager,虚类,把所有的log都保存在内存中。
- MetaSingleSnapshotLogManager, 继承自MemoryLogManager,其中的snapshot也是内存持有的,不过其getSnapshot函数返回的是MetaSimpleSnapshot。
- PartitionedSnapshotLogManager, 继承自MemoryLogManager,其中的snapshot也是内存持有的,不过其getSnapshot函数返回的是PartitionedSnapshot。实际中没有
- FilePartitionedSnapshotLogManager,继承自PartitionedSnapshotLogManager,与PartitionedSnapshotLogManager不同之处在于:PartitionedSnapshotLogManager在更新快照的时候会把快照保存在内存中,而FilePartitionedSnapshotLogManager想从tsfile中实时获取快照。笔者理解就是FilePartitionedSnapshotLogManager不想在内存中保存快照,而是在需要的时候实时从tsfile中获取快照,用以减少内存的使用。但是目前并未达到理想的效果,因为在LogManager append log的时候,已经把log保存在内存中了,所以iotdb作者起了一个issue来研究这个问题 https://issues.apache.org/jira/browse/IOTDB-439
总结
Log,LogManager和LogApplier以及Snapshot之间的关系几个组件的关系为:
- LogManager管理了log,包括log的存储,读取;
- LogManager调用了LogApplier来执行真正的操作;
- Snapshot是一种特殊的log,为了解决log过多的问题,Snapshot主要有三种:
- 包含了一组log的集合(目前实现是保存在内存中);
- 包含了一组tsfile(文件的snapshot)的集合;
- 包含了一些元数据集合的MetaSimpleSnapshot。
Server
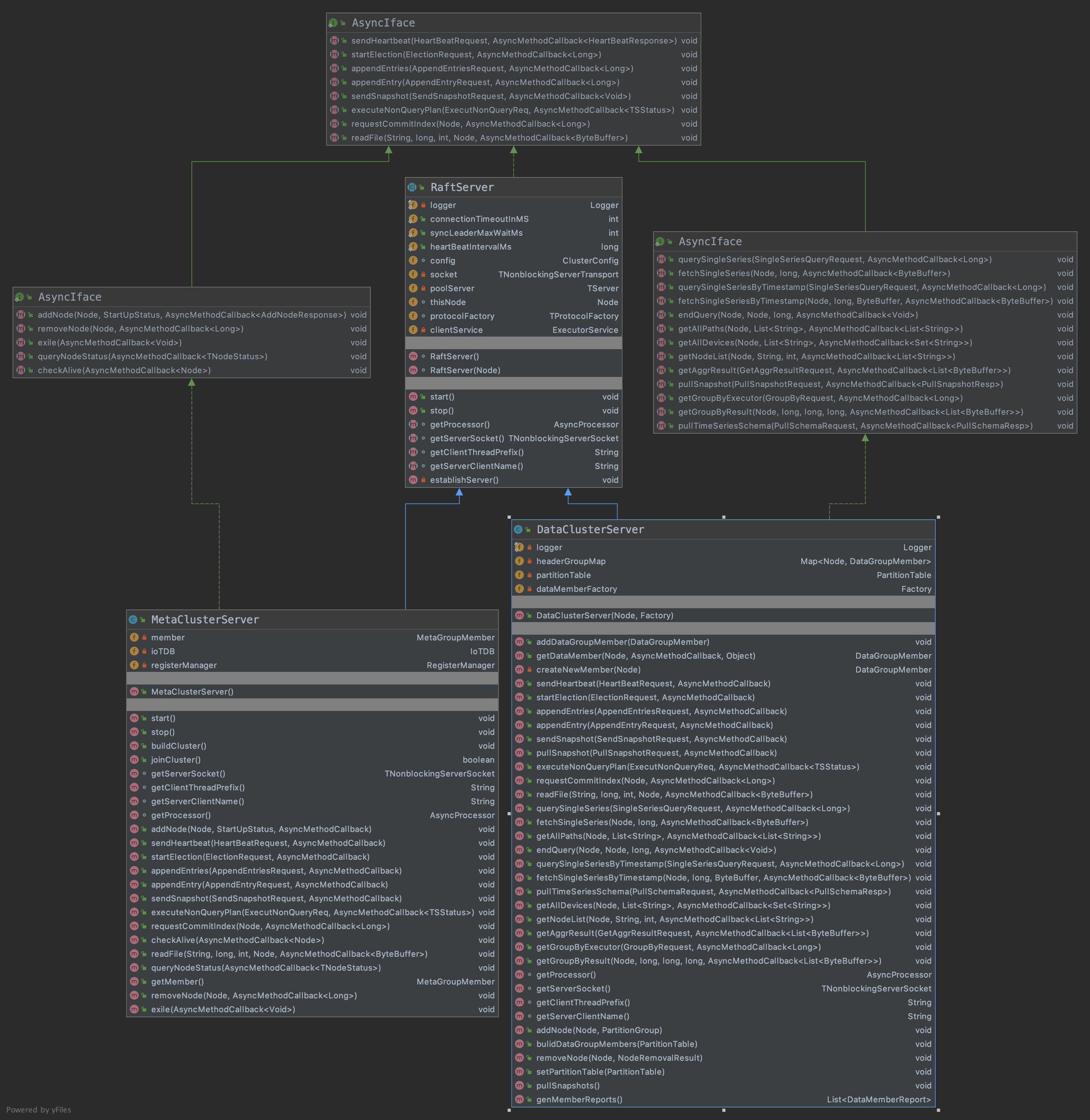
先看一下UML类图,一图胜千言,RaftServer是一个虚类,里面的函数主要是根据一些节点的配置(ip,port)等进行初始化,然后启动服务。其有两个子类,一个是DataClusterServer,主要负责data 操作相关的事情,然后通过rpc传到同一个raft组的其他节点上;另外一个是MetaClusterServer,主要负责meta数据的操作,然后把操作通过rpc传到同一个raft组的其他节点上。
RaftServer
主要包括两个大的功能:1. 初始化节点配置;2. 启动节点并且监听rpc端口服务(start()函数)
MetaClusterServer
首先看一下官方注释:MetaCluster manages the whole cluster’s metadata, such as what nodes are in the cluster and the data partition. Each node has one MetaClusterServer instance, the single-node IoTDB instance is started-up at the same time. 意思就是MetaClusterServer管理了集群中所有的meta信息,主要信息就是数据的分布了(后面会详细讲解节点的分布策略)。每个节点上都会有和一个MetaClusterServer实例(也就是说iotdb的cluster版本每个节点是同质的,假设有1000个节点,则1000个节点上都有meta服务,1000个节点组成了meta信息的raft复制组。这在性能,结果一致性上面还是有问题的),同时也会启动一个iotdb的实例。
MetaClusterServer主要变量如下:1
2
3
4
5
6// 每个clusterServer会有一个MetaGroupMember对象,后面会详细介绍。
private MetaGroupMember member;
// iotdb实例
private IoTDB ioTDB;
// 保存cluster集群一些状态,在此先不做详细介绍。
private RegisterManager registerManager = new RegisterManager();
DataClusterServer
DataClusterServer的作用就是来管理data一些数据的操作的,与MetaClusterServer不同之处在于他的RaftMember是一个map,1
2
3
4
5// key 是raft 复制组的header node, value是DataGroupMember,也就代表了一个复制组。
private Map<Node, DataGroupMember> headerGroupMap = new ConcurrentHashMap<>();
// 这个数据结构是关键,后面会详细讲解。
private PartitionTable partitionTable;
DataClusterServer的任何操作都是先要在这个map中根据rpc传过来的header,找到对应的DataGroupMember,然后再进行操作。
todo@戚厚亮,后面记得讲解PartitionTableRaftMember
先上一个官方注释。
RaftMember process the common raft logic like leader election, log appending, catch-up and so on. 也就是说,raft算法中的一些核心逻辑:领导选举、log复制、快照追赶等逻辑都是RaftMember干的。
下面介绍一下核心属性的作用:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46// the name of the member, to distinguish several members from the logs
// name就是“META/DATA”+ip+port
String name;
// to choose nodes to join cluster request randomly
// 当有新的节点加入到集群中的时候,从已经在集群中的节点中随机的选择一个节点来处理加入操作。
Random random = new Random();
protected Node thisNode;
// the nodes known by this node
protected volatile List<Node> allNodes;
AtomicLong term = new AtomicLong(0);
// 默认开始都是ELECTOR的状态
volatile NodeCharacter character = NodeCharacter.ELECTOR;
volatile Node leader;
volatile long lastHeartbeatReceivedTime;
// the raft logs are all stored and maintained in the log manager
// logManager管理了所有的log操作,详细分析请看上面logManager
LogManager logManager;
// the single thread pool that runs the heartbeat thread
// 心跳线程池,其心跳服务在HeartbeatThread类中。
ExecutorService heartBeatService;
// the thread pool that runs catch-up tasks
// catch up线程池
private ExecutorService catchUpService;
// lastCatchUpResponseTime records when is the latest response of each node's catch-up. There
// should be only one catch-up task for each node to avoid duplication, but the task may time out and in that case, the next catch up should be enabled.
// 记录节点上次追赶log的时间,用于防止一个节点建立多个追赶任务,也用于判断追赶日志超时使用。
private Map<Node, Long> lastCatchUpResponseTime = new ConcurrentHashMap<>();
// the pool that provides reusable clients to connect to other RaftMembers. It will be initialized according to the implementation of the subclasses
// client 连接池,用于复用已经创建的连接,不用每次通信都需要建立连接
private ClientPool clientPool;
// when the commit progress is updated by a heart beat, this object is notified so that we may
// know if this node is synchronized with the leader
// 两个地方用到了这个锁;1.syncLeader函数,用来同步leader的commint log index的。2.在心跳算法sendHeartbeat中,也是用来同步leader 的commit log index的。
private Object syncLock = new Object();
// when the header of the group is removed from the cluster, the members of the group should no longer accept writes, but they still can be read candidates for weak consistency reads and provide snapshots for the new holders
volatile boolean readOnly = false;
RaftMember中的重点函数解析
首先明确一点,心跳是leader发送给follower的。发送的内容是leader的commitLogTerm和commitLogIndex,来让follower更新自己的commitLogTerm和commitLogIndex。
心跳算法
- 如果follower收到的请求的term小于本地节点的term,则拒绝这次心跳请求,并且把本地节点保存的term返回给发送者,让leader更新自己的状态。
- 如果校验心跳请求参数合格的话,则会把本节点log最后更新的index发送给leader,让leader知道下次给”我”这个节点发送log的时候从哪里开始发送。
- 执行回调HeartbeatHandler.onComplete。leader会根据返回的信息做如下几个事情:
- 如果follower还承认我是leader,则根据follower发送过来的logIndex让follower追赶我的日志 ,注意LogCatchUpTask和SnapshotCatchUpTask都是leader主动给follower发送数据的,让follower进行追赶leader的日志(快照)。
- 如果follower的term比我leader的term还大,则leader主动发起退休(retireFromLeader)。
备注:此函数中有一个syncLock锁,是用来同步leader的CommitLogIndex的,只所以用锁是因为在syncLeader函数中也有同步leader的CommitLogIndex的的功能。
小提示:与etcd raft中心跳算法的不同之处在于:ectd raft心跳仅仅是leader把commitLogIndex发送给其他follower,并未返回一些信息让leader发起follower.catchUp的操作。
1 | /** |
catchUp函数
在心跳算法中讲到leader发起heartBeat请求的时候,会有一个回调,即HeartbeatHandler.onComplete,在这里面会有执行catchUp方法。下面分析下这个函数。
catchUp函数也是leader主动发起的。当leader给follower发送心跳的时候,follower会把自己的lastLogIndex返回给leader,leader据此来发起catchUp操作,给follower推送lastLogIndex之后的所有的数据。
流程如下
- 首先检查一下follower上次catchUp的时间距离现在是否小于一个阈值(20000ms),如果是则不进行catchUp。(限制catchUp的时间间隔,心跳是1000ms),
- 判断内存中log信息是否有效,有效的定义如下:要请求的日志都在内存中则视为有效(即follower还未落下很远,无需通过拉取快照进行追赶)。
- 构造follower所需的数据,根据第2步是否有效执行如下不同的内容。
- 若2有效,则通过logManager获取followerLastLogIndex之后的所有日志;
- 若2无效,则证明follower所需的日志有些已经成为快照了,所以需要拉取快照和内存中日志两部分数据。
- 向catchUpService服务(catchUpService是一个ExecutorService的线程池)中提交一个任务,任务根据第2步是否有效分为两种:(LogCatchUpTask和SnapshotCatchUpTask都实现了Runnable接口)
- 若2有效:则会创建一个LogCatchUpTask任务。这个任务就是与follower建立连接,并且遍历所有需要追赶的log,执行followr.appendEntry()即可。 注意:这里有一个优化点:可以调用followr.appendEntries()一次性把所有的log发送给follower,而不是每次都发送一条数据。
- 若2无效:则会创建一个SnapshotCatchUpTask任务。SnapshotCatchUpTask继承了LogCatchUpTask,其run方法主要内容如下:
- 把第3步中构造的快照序列化之后调用follower.sendSnapshot发送给follower;
- 发送log:执行LogCatchUpTask中doLogCatchUp,即上面讲的LogCatchUpTask类中的主要内容。
1 | /** |
选举算法
处理选举过程的算法也很简单:
- 首先看发送过来的请求的node(也就是要当leader的node)是否与本地节点保存的leader一致,如果一致我就同意。
- 如果不一致,则根据请求过来的信息与本地信息进行对比来决定是否同意发起选举的节点作为leader,其算法在processElectionRequest中。主要判断逻辑如下:
- thatTerm <= thisTerm 拒绝,发起选举的term都比我本地的要小,怎么可能给你投票!
- thatLastLogTerm < thisLastLogTerm 拒绝,发起选举的节点的最后一条日志的term都比我本地的要小,拒绝你。
- (thatLastLogTerm == thisLastLogTerm && thatLastLogId < thisLastLogIndex) 拒绝,虽然最后一条日志的term一致,但是发起选举节点的最后一条日志的索引比我本地的要小,拒绝你。
- 其他情况下就给发起选举的节点投票了。
1 | /** |
syncLeader函数
在分析心跳算法的时候,在代码注释里面提到了syncLeader这个函数。这个函数主要用来同步leader的commint log index的。
- 首先保证所有的快照下载任务都已经完成了。否则就等待所有的快照任务执行结束。
- rpc与leader节点建立通信,请求CommitLogIndex。
- 判断本地的CommitLogIndex与leader的CommitLogIndex是否一致,即follwer是否追赶上了leader的日志。如果追赶上了,则返回成功;否则未超时的情况下(20秒),等待心跳(默认1000ms,因为心跳的时候leader会使得follwer追赶自己的日志)。当等待超过20s之后若还未追赶上,则返回失败。
1 | /** |
DataGroupMember
里面就是具体的功能实现了,// TODO1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/**
* When a DataGroupMember pulls data from another node, the data files will be firstly stored in the "REMOTE_FILE_TEMP_DIR", and then load file functionality of IoTDB will be used to load the files into the IoTDB instance.
*/
private static final String REMOTE_FILE_TEMP_DIR = "remote";
/**
* The MetaGroupMember that in charge of the DataGroupMember. Mainly for providing partition table and MetaLogManager.
*/
private MetaGroupMember metaGroupMember;
/**
* The thread pool that runs the pull snapshot tasks. Pool size is the # of CPU cores.
*/
private ExecutorService pullSnapshotService;
/**
* "logManager" manages the logs of this DataGroupMember. Although the logs of different data partitions (slots) are mixed together before a snapshot is taken, after the taking of snapshot, logs of different logs will be stored separately.
*/
private PartitionedSnapshotLogManager logManager;
/**
* "queryManger" records the remote nodes which have queried this node, and the readers or
* executors this member has created for those queries. When the queries end, an
* EndQueryRequest will be sent to this member and related resources will be released.
*/
private ClusterQueryManager queryManager;
MetaGroupMember
里面就是具体的功能实现了,// TODO1
2
3// nodes in the cluster and data partitioning
// 重点是这个PartitionTable的实现,这里面包含了tsfile的数据分布,在partition章节将详细分析
private PartitionTable partitionTable;
详细函数分析
####List
此函数的功能是获取paths中每个path所对应的tsDataType,函数思路:
- 从本地获取,如果本地有则返回,否则执行第2步骤;
- 从远端获取:
- 先执行pullTimeSeriesSchemas(path) 获取这个path的schema,然后从schema中获取dataType。
- 把这些schema cache在本地。
数据分布partition
数据分布主要有以下几个类:
- PartitionGroup. 这个类继承了ArrayList
,所以实际上就是一个Node的列表,这个列表中所有的节点组成了一个raft复制组的所有节点,第一个节点记为header。 - PartitionTable是一个interface,其实现是SlotPartitionTable,其核心就是如下几个属性
1 | //The following fields are used for determining which node a data item belongs to. |
下面详细讲解一下SlotPartitionTable中的一些函数
SlotPartitionTable初始化
1 | private void init(Collection<Node> nodes) { |
getPartitionGroups函数详解
- 首先找到这个节点的索引index(所有的节点都已经按照nodeIdentifier排序了)
- 找到这个节点的上面的所有的复制组,算法如下。
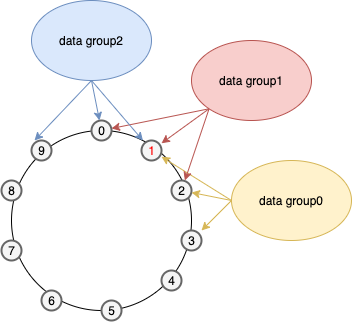
- 首先把所有的节点按照索引大小排列为一个环,如下所示(假设有10个节点),假设此节点的index为1,副本数replicaNum为3,则这个节点上面就会形成3个data group(复制组)
- 首先以节点1为起始点,顺时针找replicaNum个节点组成一个复制组,即节点1,2,3组成了一个复制组data group0,这个复制组的header为节点1;
- 然后在以节点0(节点1的上一个节点)为起始点,顺时针找replicaNum个节点组成一个复制组,即节点0,1,2组成了一个复制组data group1,这个复制组的header为节点0;
- 然后在以节点9(节点0的上一个节点)为起始点,顺时针找replicaNum个节点组成一个复制组,即节点9,0,1组成了和一个复制组data group2,这个复制组的header为节点9;
可以看到每个节点上面最多有replicaNum个复制组。getHeaderGroup(Node node)的作用就是以参数node为起始点,顺时针找到replicaNum个节点作为一个复制组然后返回。
1 | // find replicationNum groups that a node is in |
Slot与node的映射关系计算
可以详细看如下代码,思路如下:
- 计算出总的node个数: nodeRingSize;
- 求出配置的totalSlotNumbers,默认是10000个:
- 则每个node上面分配的slot数量为:slotsPerNode = totalSlotNumbers / nodeRingSize,因为这个结果并不一定是整数,则最后面的一个node上面的slot num个数可能会多一些。所以Map<Node, List
> nodeSlotMap这个数据结构就初始化好了。 - 有了Map<Node, List
> nodeSlotMap这个数据结构,则每个slot在哪个节点,即Map<Integer, Node> slotNodeMap这个数结构也就很清楚了。
1 | private void assignPartitions() { |
数据路由
以insert数据为例,其数据路由如下:
- 根据要插入数据的storageGroupName以及timestamp 进行hash,确定slotId。算法如下:
1 | public static int calculateStorageGroupSlotByTime(String storageGroupName, long timestamp, |
- 从slotNodeMap这个map中获取这个slot所在的node;
- 以此node作为header,寻找这个node作为header的PartitionGroup.
- 获取此PartitionGroup(其实是用了这个partitionGroup的header)所在的GroupMember,后续对数据的操作皆用此GroupMember对象。(代码在DataGroupMember::getDataMember中,即iotdb为每个header创建了一个DataGroupMember,然后保存在Map<Node, DataGroupMember> headerGroupMap这个数据结构中,所以通过header就可以找到这个header所属的DataGroupMember)。
节点管理
添加节点
增加节点这个操作是MetaClusterServer来处理的,MetaClusterServer收到请求之后,调用MetaGroupMember.joinCluster()来处理,这个函数的处理逻辑如下:
- 从种子节点中随机的选择一个节点(假设选择的为节点A,待加入节点为B,这个操作也是在节点B操作的,节点B执行shell脚本把自己加入到集群中),把这个添加节点的请求转发给这个节点(节点A);
- 连接节点A,给节点A发送addNode的rpc请求(最终请求到达节点A之后,是MetaGroupMember调用的add方法);
- 节点A首先看本机是否是复制组的leader,如果不是,则把请求转发给leader;否则自己处理;
- 当发现自己是所在的复制组的leader的时候:
- 检查一下节点B的参数与节点A本地的参数是否一致(PartitionInterval、HashSalt、ReplicationNum等),不一致则返回。
- 构造AddNodeLog,并且把其发送给同一个复制组(目前的实现也就是所有的节点,因为metaDataGroup所有的节点组成了一个复制组),当大多数节点收到回复的时候,即认为成功;注意:leader发送日志给follower的时候,follower仅仅把日志保存下来,并不去commit日志,commit日志只有在leader与follower通过心跳通信的时候,才让follower去commit日志,然后在走一遍状态机
- 当节点A收到大多数节点的回复的时候,节点A提交日志,提交日志的时候会走状态机,对于AddNodeLog,状态机会更新本地的partitionTabel;
- 节点A序列化本地最新的partitionTabel,返回给节点B;
- 若rpc请求返回成功:接受节点A返回的partitionTable信息,然后调用dataGroupMember.pullSnapshot 方法来追赶新复制组的数据。
- 其他情况下都是失败的,等待重试。
- 连接节点A,给节点A发送addNode的rpc请求(最终请求到达节点A之后,是MetaGroupMember调用的add方法);
- 当加入成功之后,设置自己的角色为FOLLOWER,并且启动心跳服务。结束;
- 若第一步加入失败,则等待1000ms(心跳时间)之后,再次重试,最多重试10次;
删除节点
删除节点与添加节点逻辑类似,再次不再分析