东方国信行云时序数据库CirroData-TimeS,是东方国信面对高速增长的物联网大数据市场和技术挑战推出的创新性的大数据处理产品,它不依赖任何第三方软件,TimeS是吸取众多传统关系型数据库、NoSQL数据库等软件的优点之后自主开发的产品,在时序空间大数据处理上,有着自己独到的优势。经过历时1年多的核心研发,CirroData-TimeS 0.12.1版本重磅发布。
完备的分布式时序数据库
CirroData-TimeS是针对时间序列数据收集、存储与分析一体化的数据管理引擎。它具有体量轻、性能高、易使用的特点,适用于工业物联网应用中海量时间序列数据高速写入和复杂分析查询的需求。CirroData-TimeS覆盖了对时序数据的采集、存储、查询、分析以及可视化等全生命周期的数据管理功能。具有以下特性:
丰富的功能特性:
- 类SQL查询语句,CirroData-TimeS支持类SQL查询语句,对于熟悉SQL使用的用户来说,学习成本较低,使用友好;
- 支持基于时间范围的批量数据查询、分组查询、值过滤等查询;
- 提供常用的周期聚合函数,如avg,min,max,sum。使用预处理能有效的降低采样聚合函数查询对系统的瞬时查询压力,实现数据计算一次多次查询,同时也能有效的降低查询延迟,提高用户体验;
- 提供多种语言的SDK,支持Java,C++,C#,Python,Go,JDBC等主流的SDK,方便用户使用;
- 支持自定义数据存储周期,过期数据自动删除等功能;
- 多种数据编码压缩方式,支持PLAIN编码、二阶差分编码(TS_2DIFF)、游程编码(RLE)、GORILLA编码;支持SNAPPY压缩、LZ4压缩、GZIP压缩、SDT压缩等多种压缩方式;
- 支持用户自定义函数,方便用户二次开发;
- 支持对数据库、表、用户等权限管理,从而为用户提供对于数据的权限管理功能,保障数据的安全。
- 支持高可用、数据多副本分布存储。
极致的性能体验:
- 单节点每秒千万点数据写入能力,可支持海量数据的持续写入;
- 毫秒级查询性能;
- 高压缩比,压缩比可达40倍,节省磁盘带宽。
完备的系统周边:
- 云端协同同步工具,同步工具是定期将本地磁盘中和新增的已持久化的TsFile文件上传至云端并加载到CirroData-TimeS的套件工具,支持云端协同;
- 强大的系统生态,CirroData-TimeS目前集成了Grafana、Hadoop、Spark、Hive、Fink、Zeppelin等组件,极大了丰富了CirroData-TimeS的场景和生态系统;
- 完善的系统工具,支持CSV数据导入导出、JMX工具、查询性能追踪工具、数字水印等;
- 支持MQTT物联网协议;
- 支持多种操作终端:SQL命令行终端,SQL Developer可视化终端等。
高可用分布式架构
CirroData-TimeS采用Share-Nothing的分布式架构,各个节点都是同质的,每个节点主要模块如下图所示:
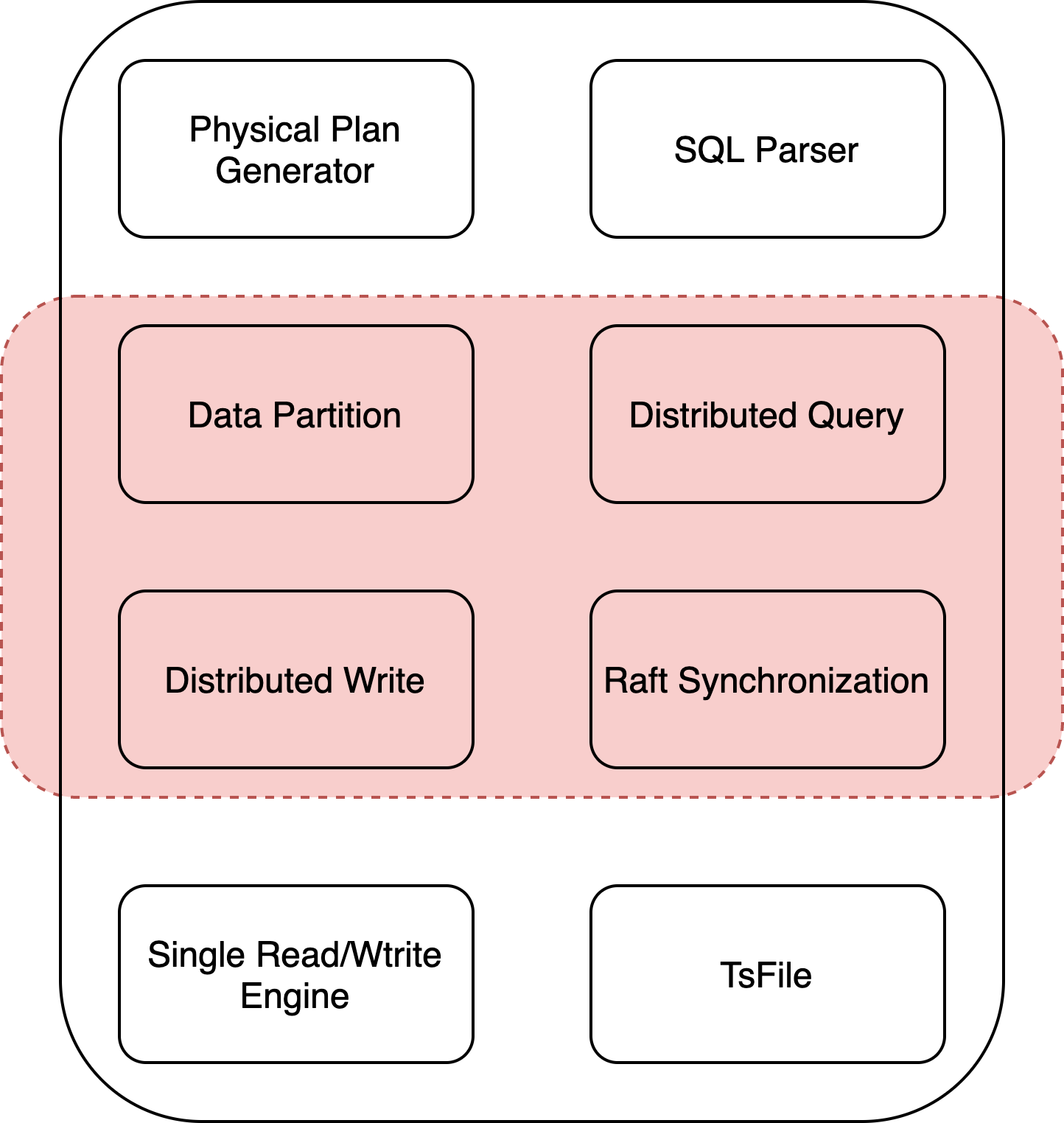
单机有如下几大模块:分别为Physical Plan Generator、SQL Parser、Single Read/Write Engine以及存储文件TsFile。分布式较单机多了如下几大模块:Data Partition、Distributed Query、Distributed Write以及各个节点之间同步协议Raft Synchronization模块。
CirroData-TimeS集群搭建之后,会根据节点的ip和port和当前启动时间生成一个hash值,所有节点按照此hash值排序形成一个环形,hash值最大的节点的后面的节点就是hash值最小的节点,集群会按照配置的副本数N,从hash值最小的节点开始,依次选择N-1个节点组成一个raft组,形成一个data raft group。所有的meta节点组成一个meta raft group。
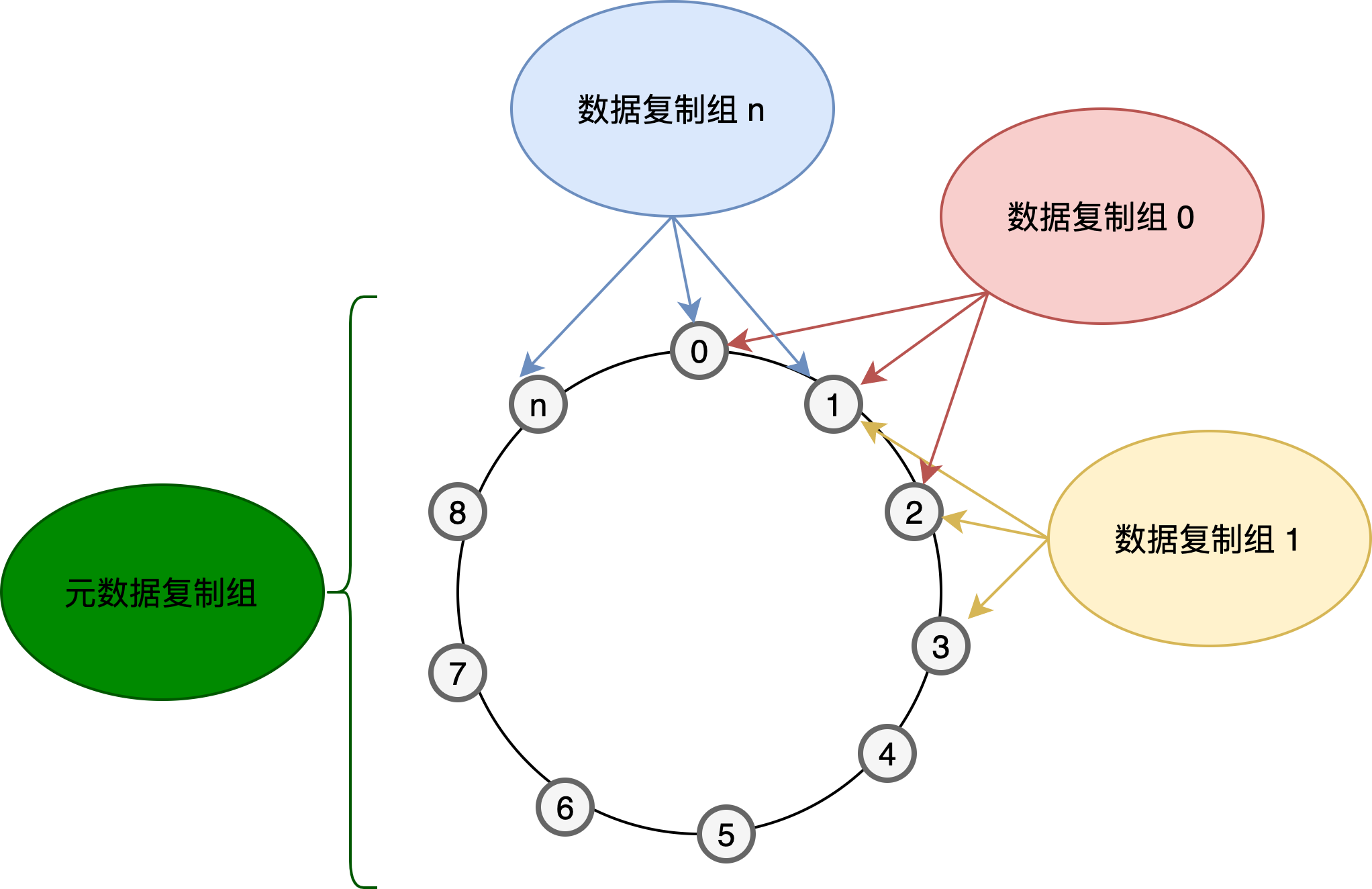
以4节点3副本为例,其会形成如下raft复制组,每个节点上面都会有N+1个复制组,N是副本数,即N个data raft group,1指的是所有节点形成一个meta raft group。
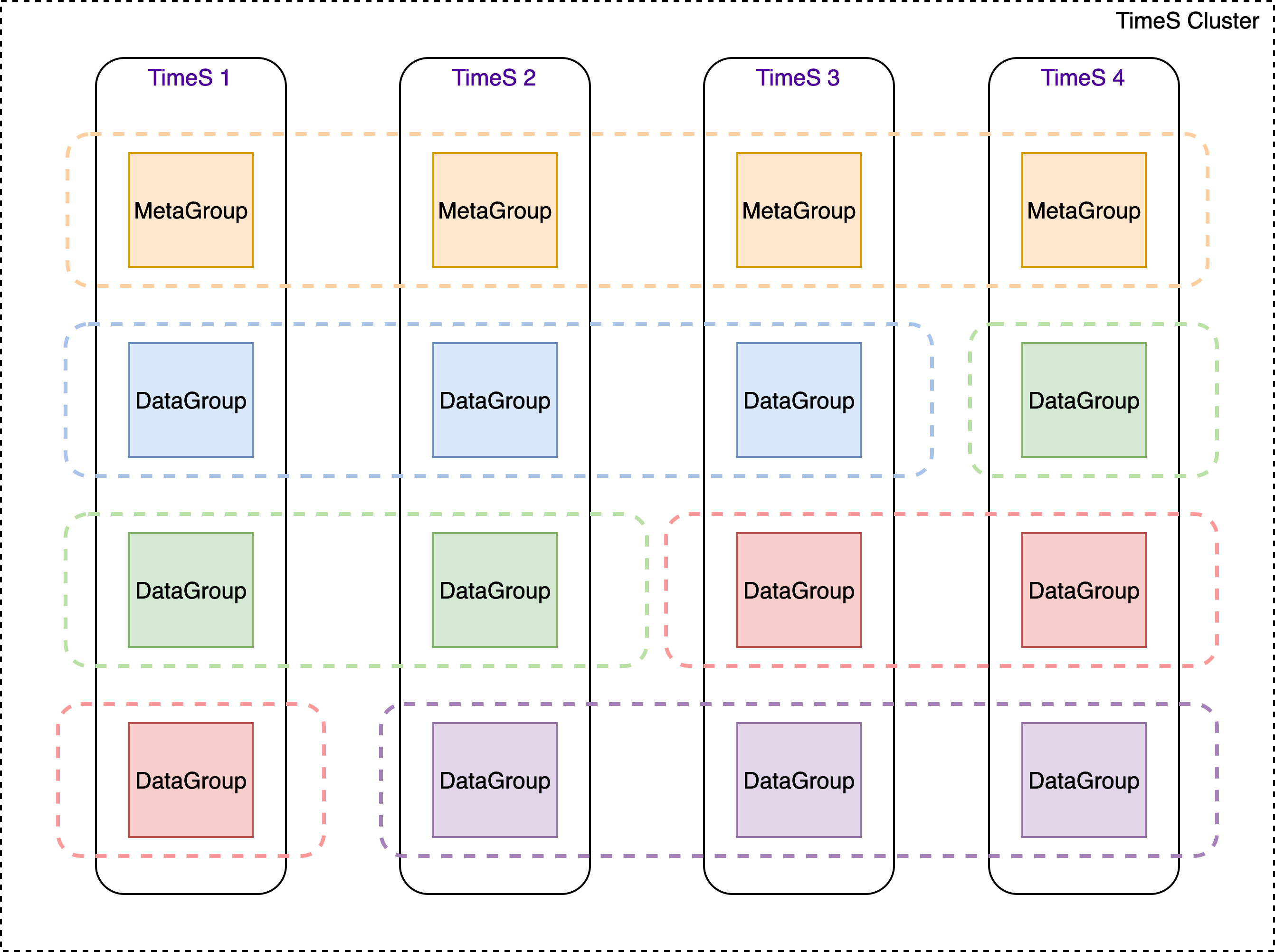
分布式数据存储
当初始化好了raft复制组之后,面临的问题就是数据归属问题,哪些raft复制组处理哪些数据呢?这就需要数据分区这个模块来解决了。
数据分区模块负责元数据、数据分布的计算工作,为了便于表述,本文在此讲述下CirroData-TimeS的一些基础概念。
CirroData-TimeS基础概念
CirroData-TimeS模型是树状结构。如下所示,有存储组、设备、测点等概念。存储组可以理解为传统数据库中的表,在存储的时候,不同的存储组的数据是存储在不同的文件夹中的。下图中有root.sgcc、root.ln两个存储组。叶子节点叫做测点,叶子节点的父节点叫做设备。从父节点root到叶子节点的全路径叫做时序。比如下图中有root.sgcc.wf01.status等4条时序。
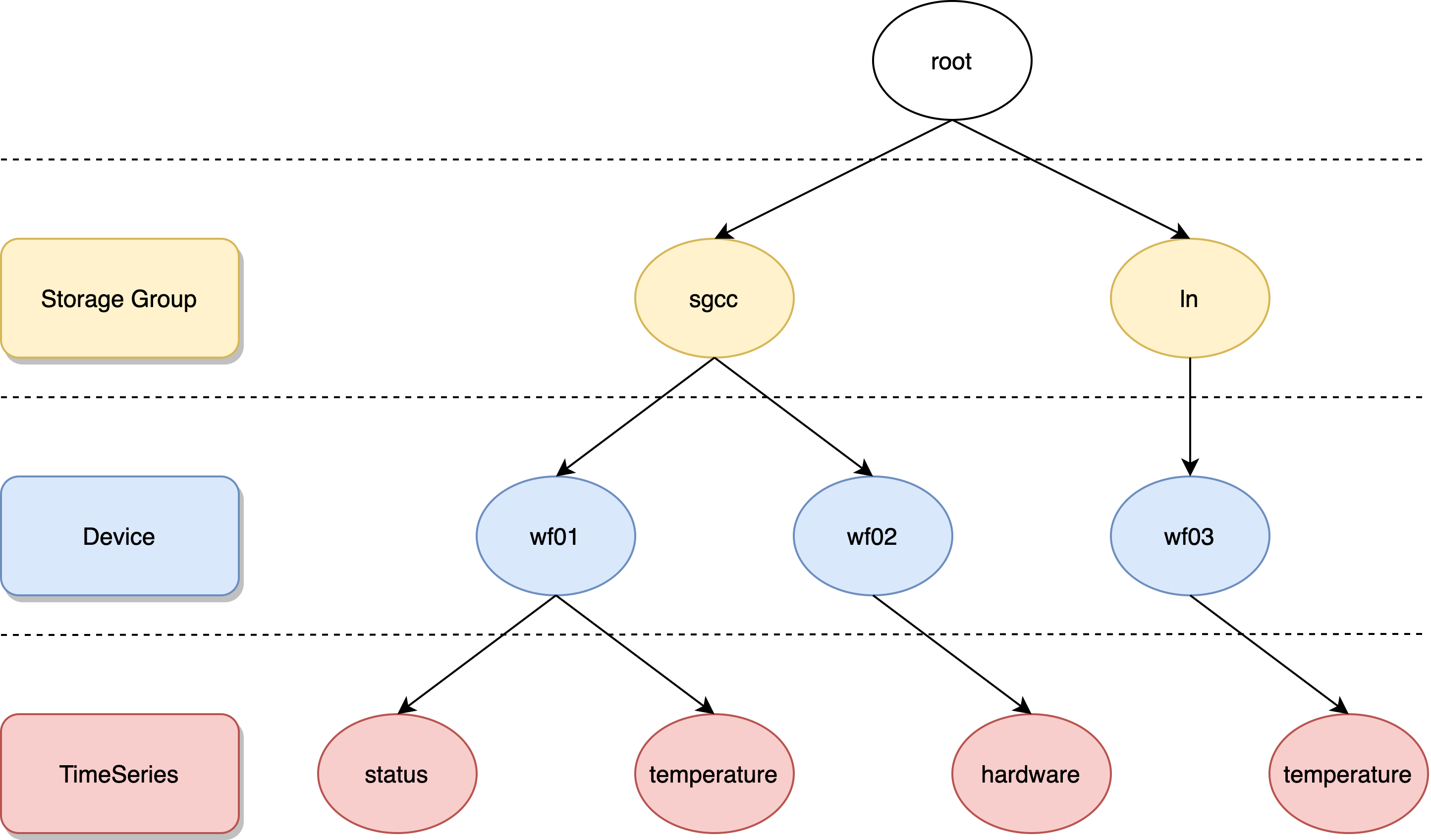
元数据分布
对于分布式CirroData-TimeS来说,有两种类型的元数据信息,一种是存储组、另外一种是时序。为什么说两种类型的元数据呢?因为这两种元数据是不同的复制组管理的。存储组是meta raft group管理的。而时序信息是由data raft group管理的。这样做的好处也是由于存储组元数据比较少,可以在各个节点保存;但是时序信息有可能比较大,有可能高达千万级别,如果每个节点都保存有相同的时序信息,每个节点会浪费太多的内存空间(这里也是内存和时间的trade off,当然每个节点都有时序的元数据信息是最好的,因为写入、查询会用到这些时序元数据信息。关于这部分考虑将在后面的文章中进行详细分析)。所以会把这些时序数据信息分散到各个节点进行管理。
存储组分布
对于存储组这样的元数据,由于是meta raft group管理的。所以在每个节点都会保存。
时序分布
对于时序和数据的存储,是分布到多个节点进行分散存储的。分布的核心是一个数据分区算法,即如何判定我的(元)数据应该存储在哪个节点上?
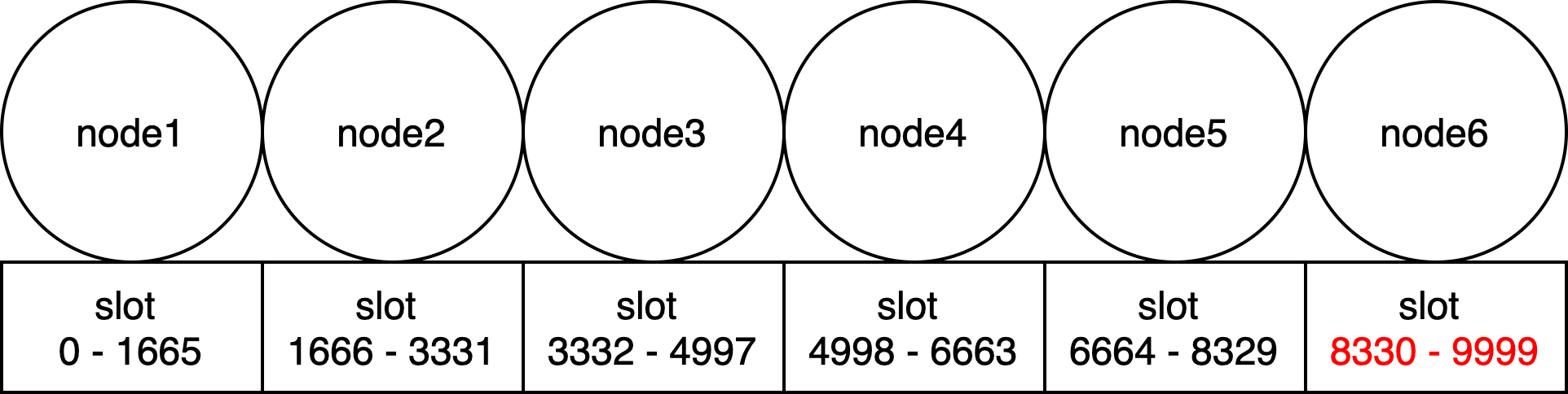
TimeS系统中预先设置了10000个slot,然后会均匀的把这些slot分到集群中各个TimeS实例中,假设节点数是M,则集群环中的前M-1个节点每个节点分配的slot数是10000/M,最后一个节点是slot数就是10000-10000/M*(M-1),可能较前M-1个节点会多一些。
比如,在6个节点组成的集群的情况下,第一个节点会分配0-1665共1666个slot;第二个节点会分配1666-3331共1666个slot;第三个节点会分配3332-4997共1666个slot;第四个节点会分配4998-6663共1666个slot;第五个节点会分配6664-8329共1666个slot;而第六个节点就会分配8330-9999共1670个slot。
得到了节点和slot id的关系,剩下的就是如何把数据映射到slot中。CirroData-TimeS采用了如下hash算法:
1 | slot_id = hash(storage_group, time_partition) % total_slot_num |
storage_group即存储组的名字,time_partition会根据元数据操作还是数据操作,执行不同的策略。
在计算时序的分布的时候,time_partition永远等于0,即可以理解为同一个存储组的所有时序都是保存在同一个data raft组中的。
数据分布
数据分布与时序元数据分布的计算公式都是一致的,区别在于其time_partition不是0,而是计算出来的。1
2time_partition = time_stamp % partition_interval
slot_id = hash(storage_group, time_partition )% total_slot_num
time_stamp是数据插入的时间戳,而partition_interval是时间分区,比如一周、一个月等。由于同一个时间分区的数据是保存在一起的,对于查询和过期数据删除都有优势。
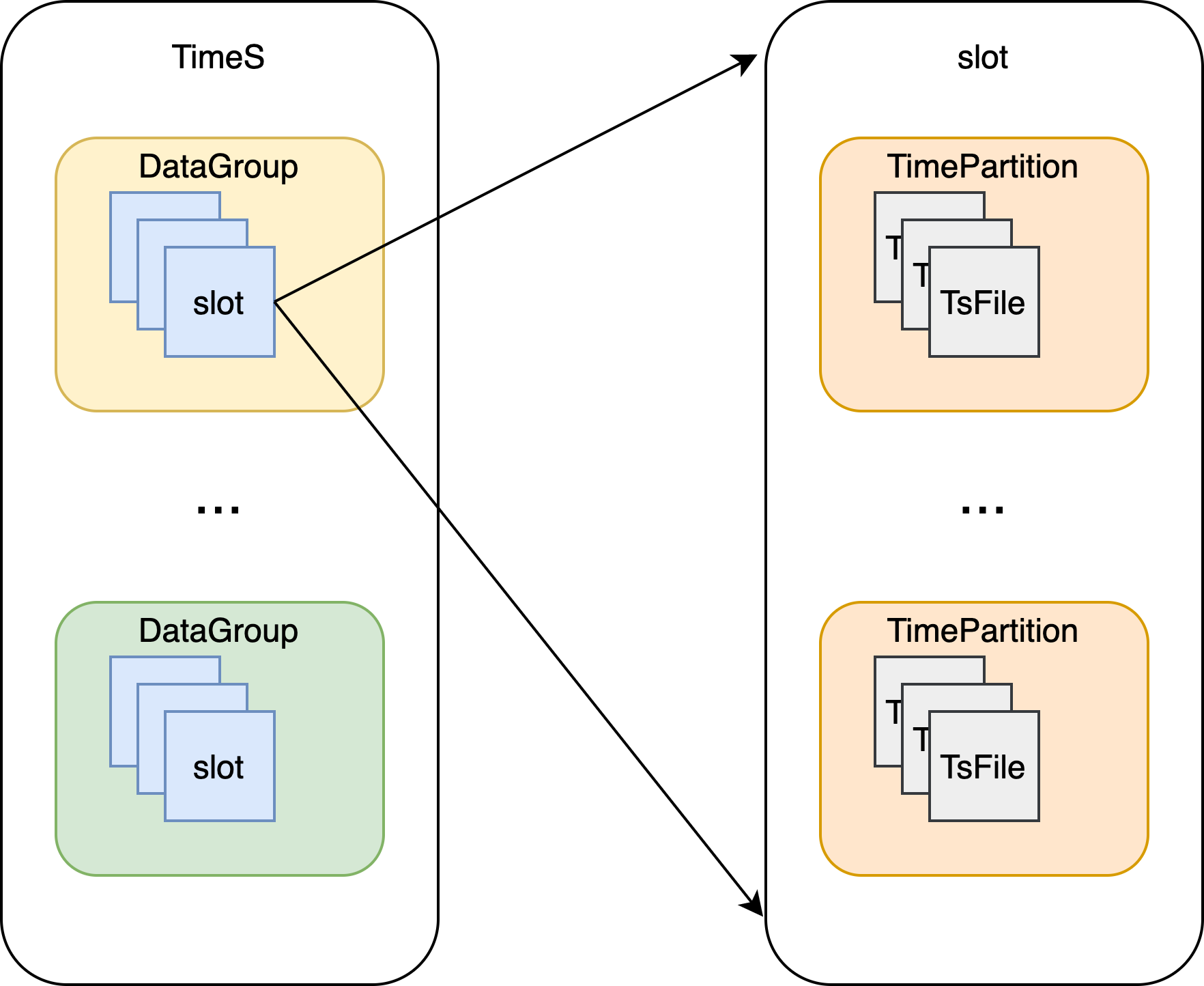
如下所示,每个data raft group会有许多的slot,每个slot上面会有多个time partition,每个partition会有多个TsFile,一个TsFile会有属于这个时间分区的多条时序的具体数据,关于TsFile的详细描述,请参考前面几篇文章。
性能对比
我们与InfluxDB做了性能对比测试,由于InfluxDB分布式版本未开源,所以我们只对其做了单机版本的性能测试。benchmark采用TimeS-Benchmark,其主要配置如下所示:
测试方案
本测试主要测试测点少、测点多两种场景下,各个数据库的写入性能、查询性能以及数据压缩比。测点少情况模拟设备数量为300,每个设备20个测点,共计6000个测点;测点多的场景模拟设备数量为80000,每个设备100个测点,共计800万个测点;写入数据类型和时间戳精度如下所示:
| 属性 | 值 | 备注 |
|---|---|---|
| 时间戳精度 | ms | 写入的时间戳精度 |
| 数据类型 | DOUBLE, BOOLEAN, INT32, INT64, FLOAT | 写入的数据类型 |
测试环境
硬件环境
| 硬件 | 参数 |
|---|---|
| cpu | 40核,Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz |
| 内存 | 256GB |
软件环境
| 软件 | 参数 |
|---|---|
| CirroData-TimeS | CirroData-TimeS-0.12.1 |
| InfluxDB | InfluxDB-1.8.0 |
| 内存 | 64GB(测试少测试场景)、128GB(测试多测试场景) |
CirroData-TimeS分布式采用3节点3副本部署。
测试结果
写入
测点少场景
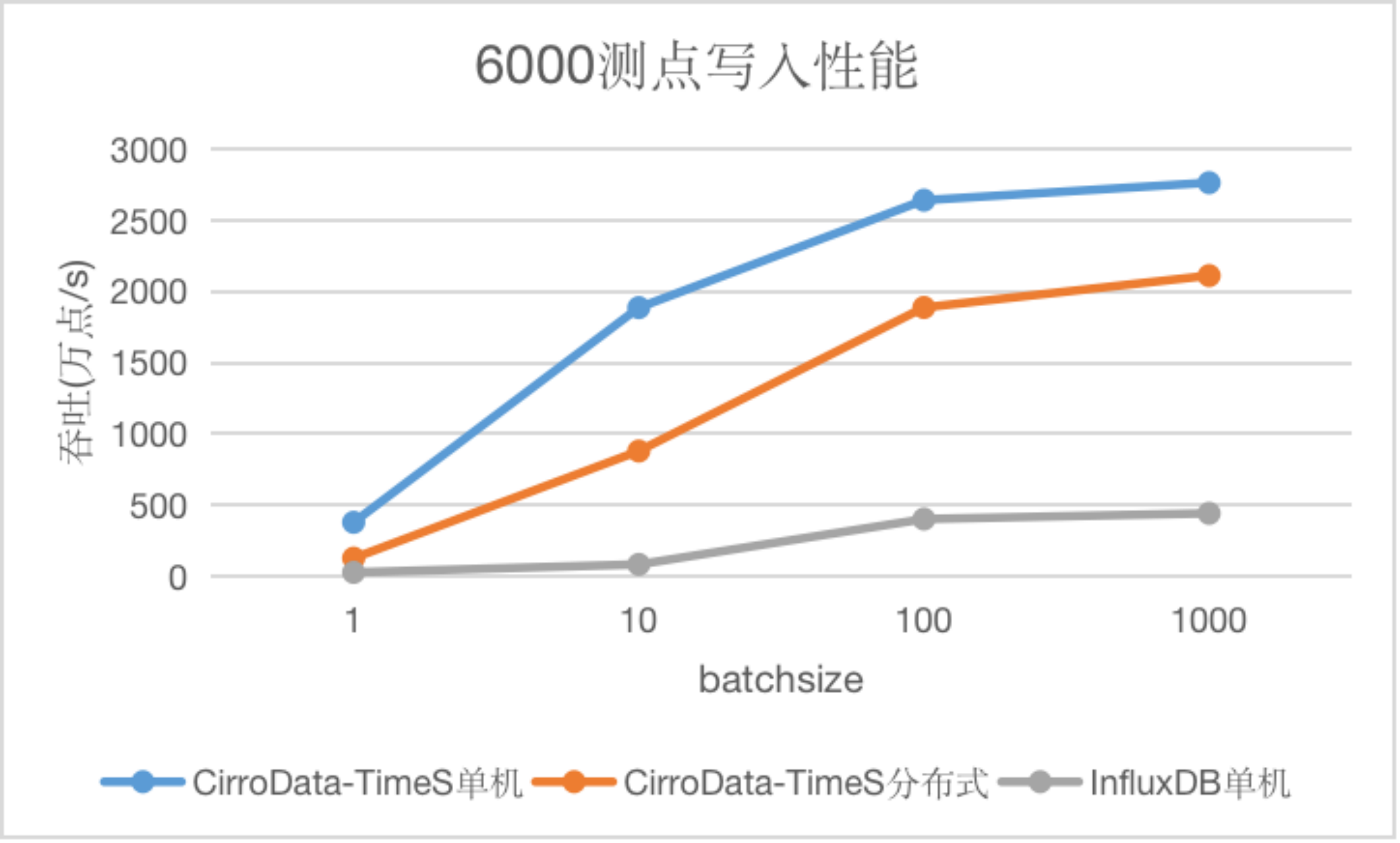
测点少场景下,随着batchsize的增大,InfluxDB性能逐渐趋于平稳,达到阈值,而CirroData-TimeS无论是单机还是分布式均呈现上升趋势。CirroData-TimeS单机吞吐是InfluxDB的6.2-23倍,CirroData-TimeS分布式吞吐是InfluxDB的4.7-10.7倍
测点多场景
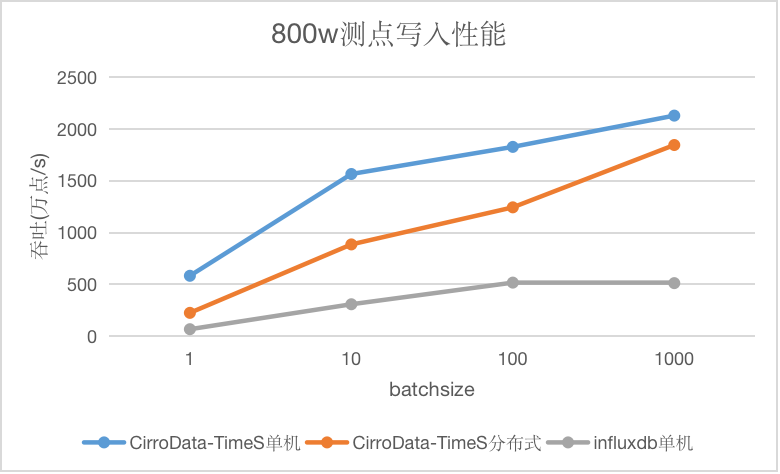
测点多场景下,随着batchsize的增大,InfluxDB性能逐渐趋于平稳,达到阈值,而CirroData-TimeS无论是单机还是分布式均呈现上升趋势。CirroData-TimeS单机吞吐是InfluxDB的3.5-8.8倍,CirroData-TimeS分布式吞吐是InfluxDB的2.4-3.6倍
查询
对于每种数据库,我们采用如下8种查询:
| 查询 | 备注 |
|---|---|
| Q1 | 精确点查询 select v1… from data where time = ? and device in ? |
| Q2 | 范围查询(只限制起止时间)select v1… from data where time > ? and time < ? and device in ? |
| Q3 | 带值过滤的范围查询 select v1… from data where time > ? and time < ? and v1 > ? and device in ? |
| Q4 | 带时间过滤的聚合查询 select func(v1)… from data where device in ? and time > ? and time < ? |
| Q5 | 带值过滤的聚合查询 select func(v1)… from data where device in ? and value > ? |
| Q6 | 带值过滤和时间过滤的聚合查询 select func(v1)… from data where device in ? and value > ? and time > ? and time < ? |
| Q7 | 分组聚合查询(GROUP BY) |
| Q8 | 最近点查询 select time, v1… where device = ? and time = max(time) |
测点少场景
在测点少的场景下,为了验证查询不同数据量的性能,针对时间范围的查询,设计了查询时间间隔分别为1s,1min,1h和1d的4种查询,对应查询结果集数量为10,100,10000,100000不等。
Q1
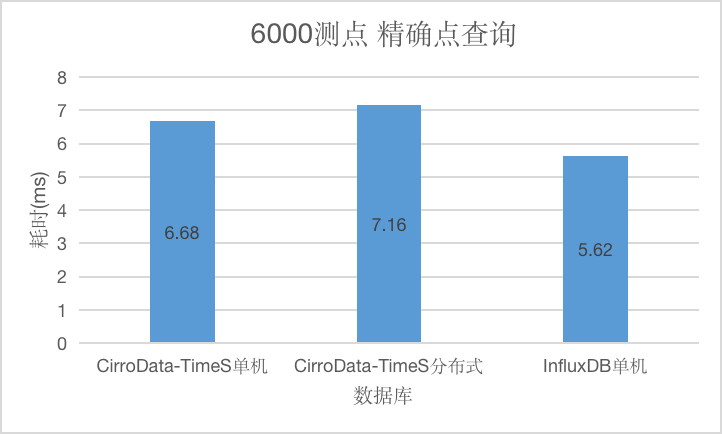
对于精确点查询,CirroData-TimeS单机,分布式以及InfluxDB查询延迟均在10ms以内。
Q2
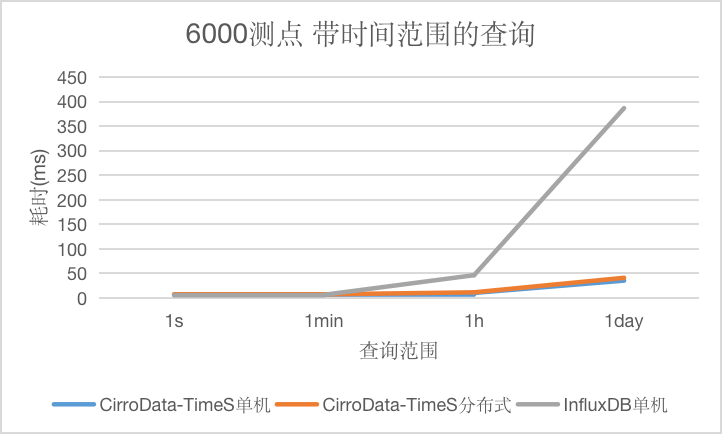
对于带时间范围的查询,CirroData-TimeS不论是单机还是分布式均比InfluxDB好,特别是查询的数据量大了之后,CirroData-TimeS查询性能是InfluxDB的10.96倍。这是因为CirroData-TimeS压缩比比InfluxDB高很多,读取同样的数据量,消耗的io资源比较少,就能获得更好的查询性能。
Q3
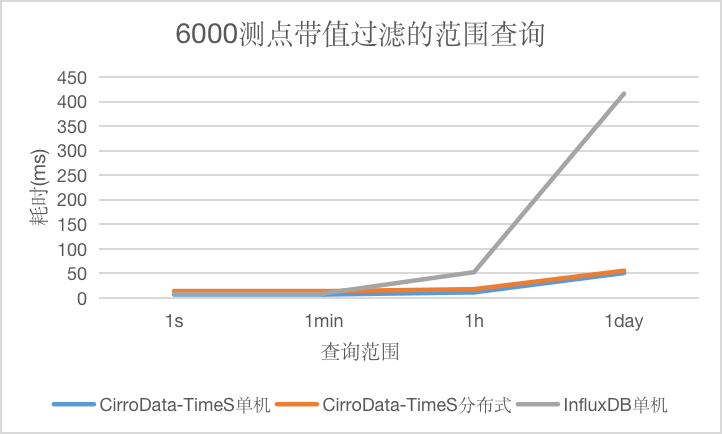
对于带值过滤的范围查询,CirroData-TimeS不论是单机还是分布式查询性能均比InfluxDB好,特别是查询的数据量大了之后,CirroData-TimeS查询性能是InfluxDB的8.23倍。这是因为CirroData-TimeS压缩比比InfluxDB高很多,读取同样的数据量,消耗的io资源比较少,就能获得更好的查询性能。
Q4
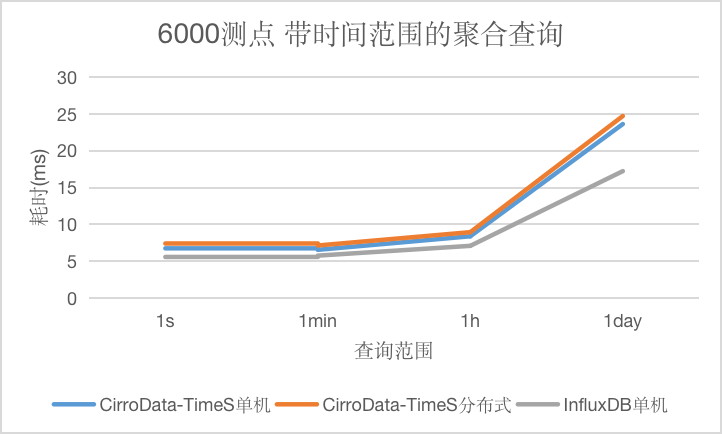
对于带时间范围的聚合查询,CirroData-TimeS单机,分布式以及InfluxDB查询延迟均在25ms以内。
Q5
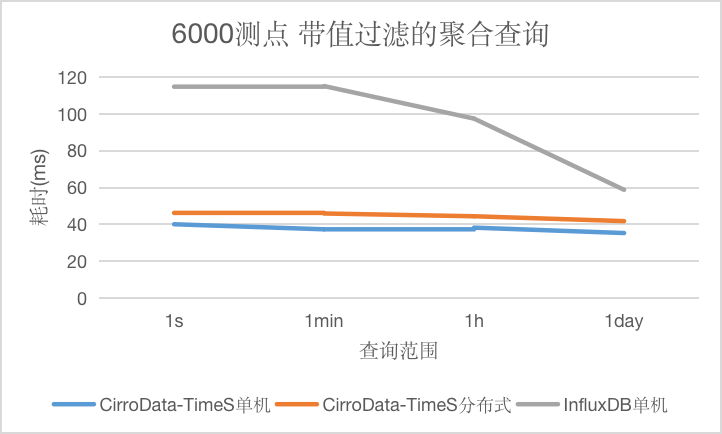
对于带值过滤的聚合查询,本种查询条件里不包含时间条件,CirroData-TimeS查询性能不论是单机还是分布式均比InfluxDB好,最高达到它的2.86倍,并且能维持比较稳定的查询延迟。上面比较奇怪的是InfluxDB的查询延迟会下降,猜测是测试误差。
Q6
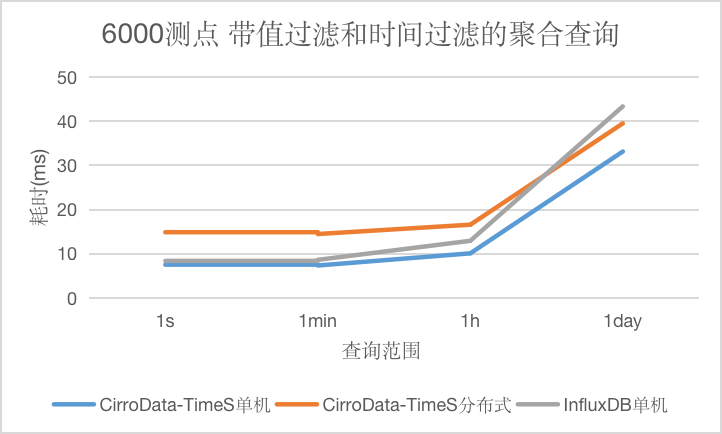
对于带值过滤和时间过滤的聚合查询,随着查询数据量的增大CirroData-TimeS不论是单机还是分布式查询性能均比InfluxDB好,最高可达到InfluxDB的1.31倍。
Q7
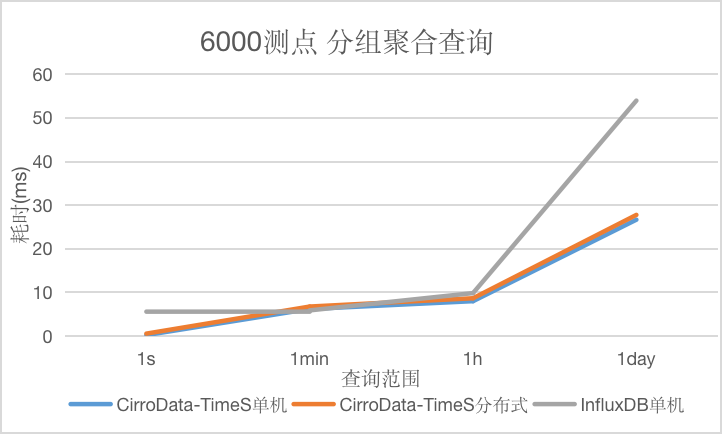
对于分组聚合查询,随着查询数据量的增大CirroData-TimeS不论是单机还是分布式查询性能均比InfluxDB好,最高可达到InfluxDB的2.02倍。
Q8
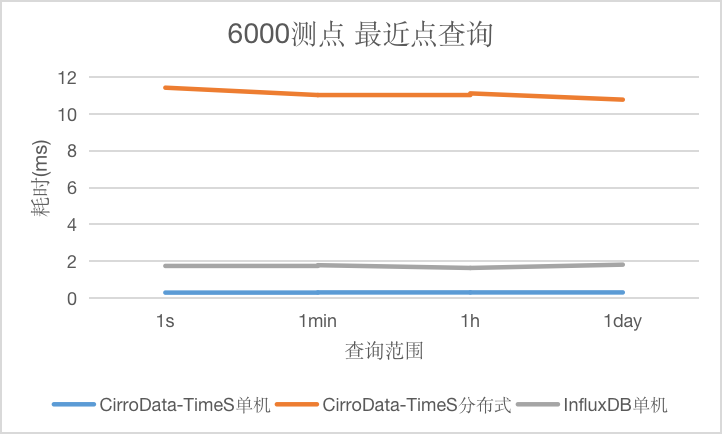
对于最近点查询,和查询时间范围无关,CirroData-TimeS单机,分布式以及InfluxDB查询延迟均在12ms以内。CirroData-TimeS单机的查询性能可以达到InfluxDB的6倍。
测点多场景
在测点多的场景下,为了验证查询不同数据量的性能,针对时间范围的查询,设计了查询时间间隔分别为1s,1min,1h和6h的4种查询,对应查询结果集数量为10,100,4000,20000不等。
Q1
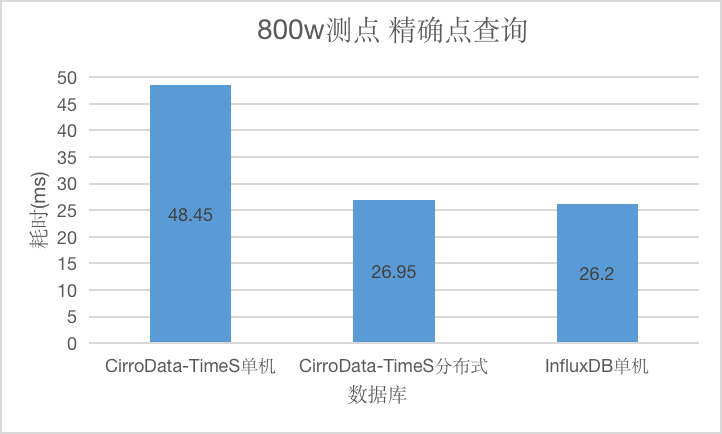
对于精确点查询,和查询时间范围无关,CirroData-TimeS单机,分布式以及InfluxDB查询延迟均在50ms以内。
Q2
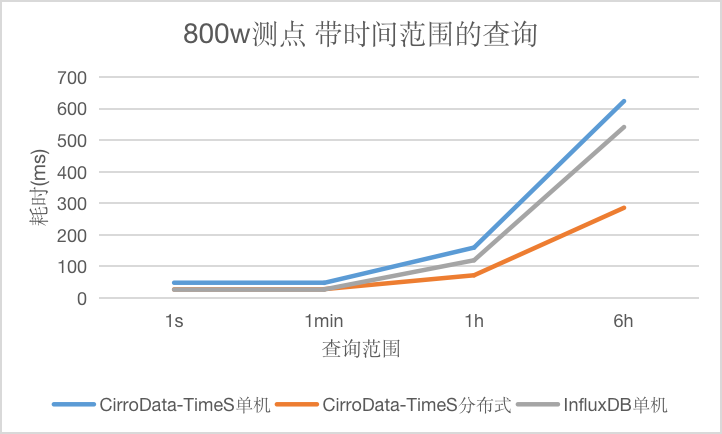
对于带时间范围的原始数据查询,CirroData-TimeS分布式查询性能比InfluxDB好,单机查询性能略比InfluxDB差。随着数据量增大,单机版本查询延迟都会增长比较快,而CirroData-TimeS分布式查询延迟增长比较慢,这是因为分布式多个节点都可以提供查询,分摊查询压力,查询性能最高可以达到InfluxDB的1.89倍。
Q3
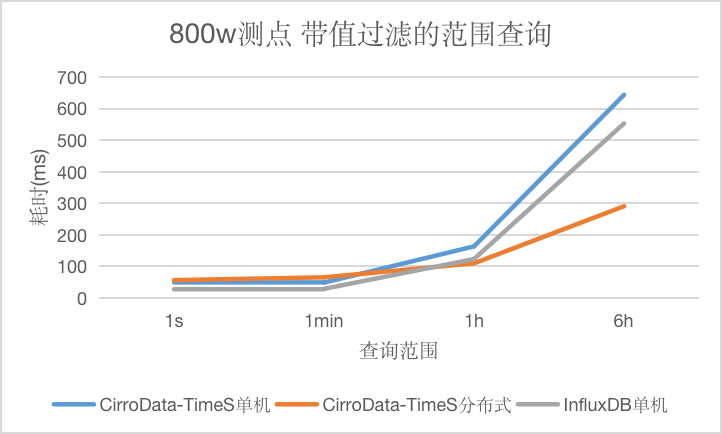
对于带值过滤的范围查询,CirroData-TimeS分布式查询性能比InfluxDB好,单机略比InfluxDB差,随着数据量增大,单机版本查询延迟都会增长比较快,而CirroData-TimeS分布式查询延迟增长比较慢,这是因为分布式多个节点都可以提供查询,分摊查询压力,查询性能最高可以达到InfluxDB的1.90倍。
Q4
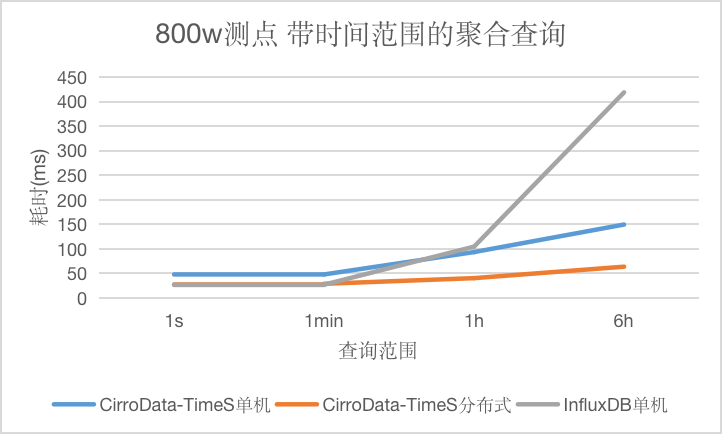
对于带时间范围的聚合查询,CirroData-TimeS查询性能不论是单机还是分布式均比InfluxDB好,特别是查询的数据量大了之后,CirroData-TimeS查询性能是InfluxDB的6.58倍。这是因为CirroData-TimeS压缩比比InfluxDB高很多,读取同样的数据量,消耗的io资源比较少,就能获得更好的性能。
Q5
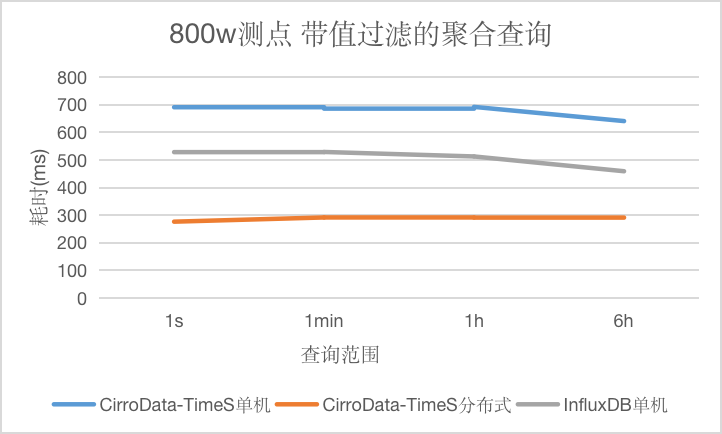
对于带值过滤的聚合查询,和查询时间范围无关,CirroData-TimeS单机,分布式以及InfluxDB查询延迟均在700ms以内。CirroData-TimeS分布式查询性能可以达到InfluxDB的1.9倍。
Q6
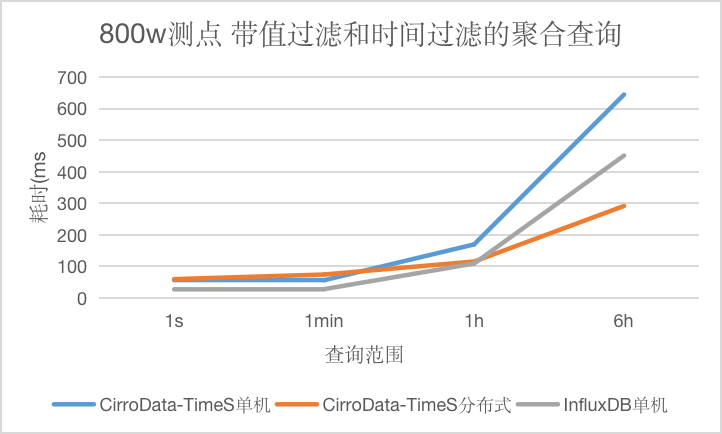
对于带值过滤和时间过滤的聚合查询,CirroData-TimeS分布式查询性能比InfluxDB好,单机查询性能略比InfluxDB差,随着数据量增大,单机版本的查询延迟都会增长比较快,而CirroData-TimeS分布式查询延迟增长比较慢,这是因为分布式多个节点都可以提供查询,分摊查询压力,查询性能最高可以达到InfluxDB的1.54倍。
Q7
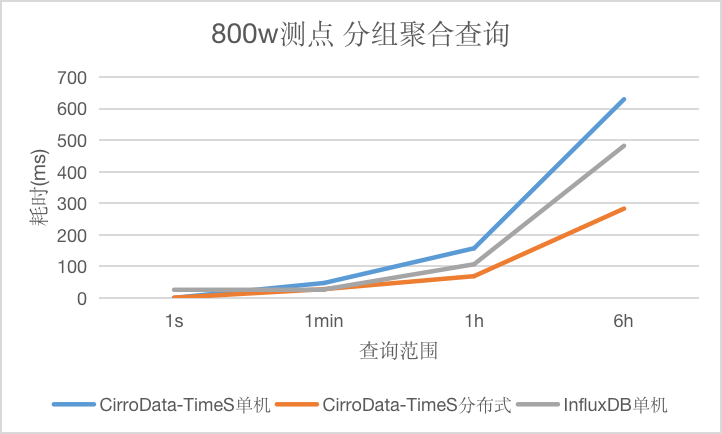
对于分组聚合查询,CirroData-TimeS分布式查询性能比InfluxDB好,单机略比InfluxDB差,随着数据量增大,单机版本查询延迟都会增长比较快,而CirroData-TimeS分布式查询延迟增长比较慢,这是因为分布式多个节点都可以提供查询,分摊查询压力,查询性能最高可以达到InfluxDB的1.7倍。
Q8
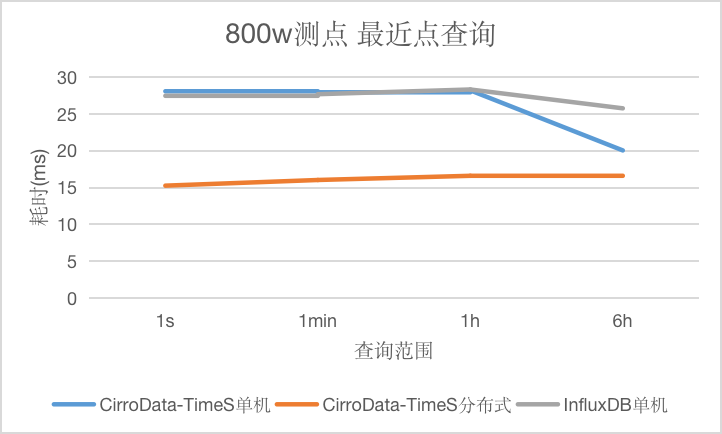
对于最近点查询,本种查询条件里不包含时间条件,CirroData-TimeS查询性能不论是单机还是分布式均比InfluxDB好,最高达到它的1.8倍。上面比较奇怪的是三者查询延迟均有上升或者下降趋势,猜测是测试误差。
压缩比
测点少场景
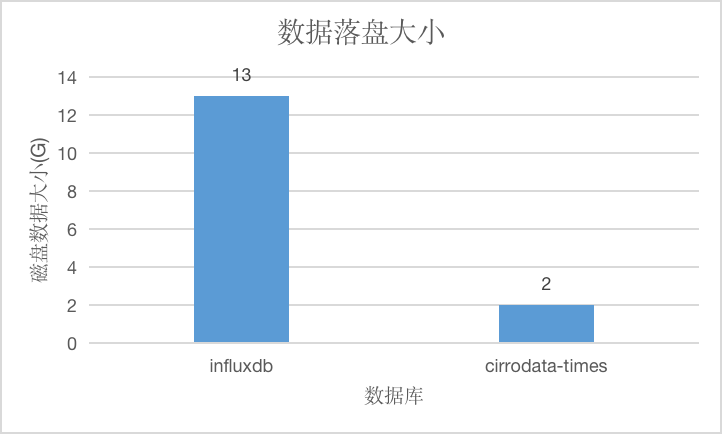
在测点数为6000的情况下,数据总量为60亿点,原始数据大小约为84GB,CirroData-TimeS压缩后的数据只有原始数据的1/42,压缩比是InfluxDB的6.5倍。
测点多场景
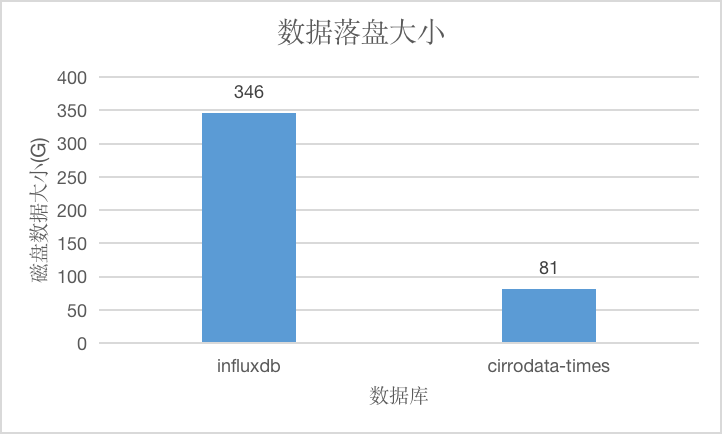
在测点数为800万的情况下,数据总量约为1600亿点,原始数据大小约为2080GB,CirroData-TimeS压缩后的数据只有原始数据的1/25,压缩比是InfluxDB的4.3倍。
总结
本文介绍了CirroData-TimeS一些特性,着重分析了CirroData-TimeS高可用分布式架构以及分布式数据存储,并且与InfluxDB做了系统的性能对比测试。
测试结果显示,不管在测点多还是测点少的场景下,CirroData-TimeS单机和分布式的写入性能均要优于InfluxDB。在测点少的情况下,随着batchsize的不同,CirroData-TimeS单机吞吐是InfluxDB的6.2-23倍,CirroData-TimeS分布式吞吐是InfluxDB的4.7-10.7倍。在测点多的情况下,随着batchsize的不同,CirroData-TimeS单机吞吐是InfluxDB的3.5-8.8倍,CirroData-TimeS分布式吞吐是InfluxDB的2.4-3.6倍。
查询场景中点查询CirroData-TimeS略差于InfluxDB,但是均可以在50ms之内返回结果。对于其他种类的查询,不管在测点多还是测点少的情况下,CirroData-TimeS均优于InfluxDB,根据查询类别的不同,在测点少的场景下,CirroData-TimeS查询性能最高是InfluxDB的10.96倍,在测点多的场景下,CirroData-TimeS查询性能最高是InfluxDB的6.58倍。
并且CirroData-TimeS拥有较高的压缩比,在测点少的情况下,CirroData-TimeS压缩后的数据只有原始数据的1/42,压缩比是InfluxDB的6.5倍。在测点多的情况下,CirroData-TimeS压缩后的数据只有原始数据的1/25,压缩比是InfluxDB的4.3倍。高的压缩比能降低磁盘io消耗,也是CirroData-TimeS优秀的查询性能的核心原因之一。
可以看到不管是写入吞吐,还是查询性能,或是数据压缩比,CirroData-TimeS都具有极致的性能,具备应对高速增长的物联网大数据市场和技术挑战的能力。